

寄稿:株式会社アイエステクノポート
DX、及びモダナイゼーションを推進していくにあたり、「DBデータの整合性が取れていること」は実は非常に重要です。
アプリケーションの最新化に際し、「今まで問題なく動いていたのだから、データにも不具合はない。整合性は取れている」と判断していると、思わぬ落とし穴に陥る場合があります。長期にわたって安定運用されているアプリケーションであっても、不整合データが潜在化していることがままあります。不整合データを含むデータを最新化されたアプリケーションで利用したり、クラウド環境で送受信したりすると、処理がエラーで異常終了する可能性があります。そのため、IBM iを活用したモダナイゼーション及びDXの推進を計画する過程で、「現行のIBM iのDBデータにエラーがないか、整合性が取れているか」の確認を行うべきでしょう。しかし、大量に蓄積されたデータの整合性を検証し、必要に応じて修正を行うには多大な工数と時間を要します。
今回は、弊社製品「i-T4db」を活用し、データ品質向上・活用を効率的に行う方法についてご紹介いたします。
i-T4dbとは?
i-T4dbとは、アイエステクノポート社が2018年より販売を開始した、下図のような効果をお客様にご提供するための製品です。
利用シーンとして下表のようなケースが想定されます。
| ユースケース | i-T4db導入効果 |
|---|---|
| DX/モダナイゼーションの実施 | 不正データの検出・修復により、Web APIやSQLを活用した新アプリケーションの正常動作を支援 |
| 他サーバーからIBM iへの移行 (コンバージョン、マイグレーション) | データベースの移行が正常であることを効率的に検証(文字・十進フィールドの不整合の検出と修復) |
| 文字コードの最新化 (CCSID 1399への移行) | 文字データの整合性を検証。IBM iで利用可能な漢字を1990年代のWindows 3.1JレベルからJIS2004レベルに引き上げ、同時に英小文字を利用可能とするには、正常なデータを前提としたコード変換が必要 |
| 日常運用の支援 | 定期的、あるいは随時(他サーバーとのデータ交換時など)にデータ整合性のチェックを実施することにより、不整合データによるアプリケーション障害を防止。あるいは、アプリケーション障害時に原因の切り分けの一つとしてデータの整合性を確認 |
これらのユースケースに対応するため、i-T4dbは2つのデータ保守機能を提供します。
● CHKPFDTA(物理ファイルデータチェック)
物理ファイルのデータ整合性チェック機能
- シフト文字、フィールドの整合性をチェック。
- 不正文字を検出し、監査ログを出力。
- シフト補正や不整合データ初期化などの自動修復。
● EDTDTA(データベースレコードの編集)
高機能データ編集機能
- DFUで編集できない不正データも編集可能。
- 16進数、文字のいずれでも編集可能。
- 132桁画面での編集が可能。
i-T4dbでは多くの画面でキーボード/マウスを利用して容易に操作できます。データベース一覧画面からRUNQRYやUPDDTAなど、データに関連するOSコマンドを右クリックで呼び出して実行することもできます。主要な機能はコマンド化されており、ユーザーアプリケーションに組み込むことが可能です。
また、アイエステクノポートでは自社で100%開発を行っているため、製品のマニュアルはもちろん、画面や印刷出力なども。すべて日本語で表記されています。
▲i-T4db メニュー画面
▲ヘルプ画面の例。すべて日本語で表示される
IBM iのDX/モダナイゼーションにおけるデータベース視点の課題に対応
次に、これらの機能がどのようにDX/モダナイゼーションに影響するか、データベースのデータ整合性の観点から具体的な例で解説します。
モダナイゼーションの実施にあたり、Db2 for iのデータ取得を従来のRLA(Record Level Access:レコードレベルアクセス)+DDSからSQLに変えるケースも増えています。業界標準であるSQLは、RPGやCOBOLの組み込みSQLや、多くのオープン系言語からJDBC/ODBCなどのDBドライバー経由で、一貫性のあるデータベース操作を行うことができます。また、IBM iのSQLはJSONやWebサービスに対応しており、先端機能を実装したアプリケーションの開発が容易になります。
しかし、SQLの利用にあたり、データの不整合が問題になるケースがあります。
①不正な十進数
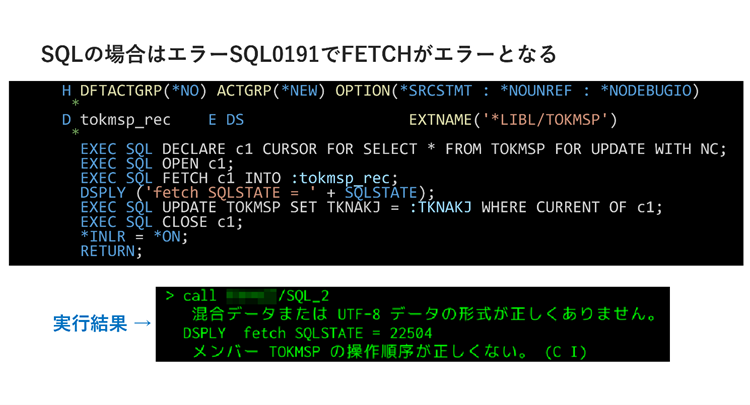
一つ目の例として、全フィールドの中で1フィールドだけ「不正な十進数」を含むレコードを読み取る場合、SQLとRLAではどのように処理されるかを具体的なコードで確認しましょう。
まずSQLの場合、レコードのFETCH(一行読み取り)でエラーとなり、転送先変数(例では:tokmsp_rec)のすべての変数が更新されません。エラーを回避するには、SELECT文に「正常な」データを含むフィールドのみを記述する、あるいは「正常な」データを含むフィールドのみのViewを作成する、といった対応が考えられます。
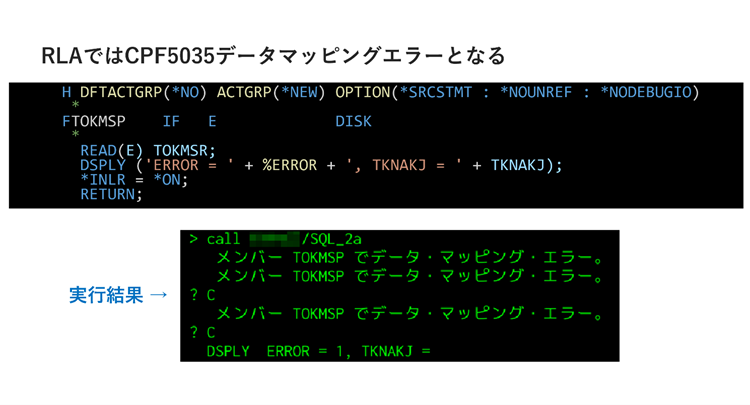
一方で、RLAではプログラムで使用されている変数のみが参照されるため、不整合データのあるフィールドをプログラムで使用していなければエラーにならず、処理はそのまま続行されます。
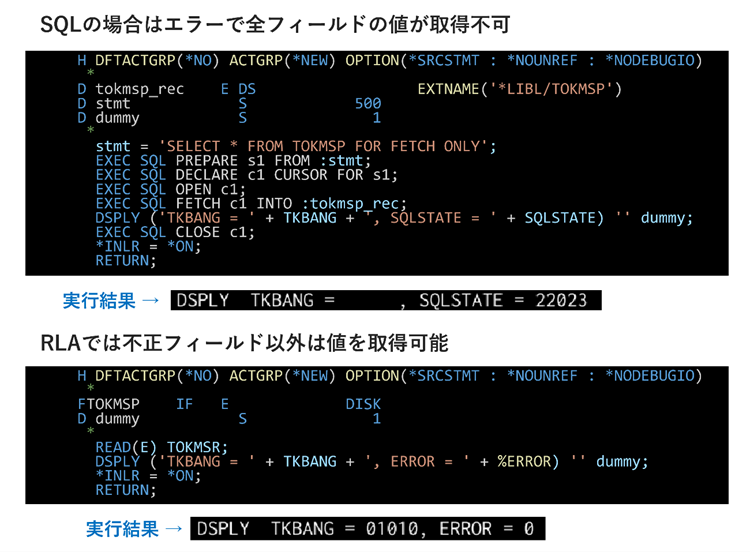
▲SQLとRLAでの実行結果比較
不正データを含むフィールドを参照した時点でエラーになるのはSQL/RLAとも同様ですが、SQLではどのフィールドに不整合データがあるかが事前にわかっていないと対応は難しいでしょう。
潜在化した不整合データを発見するのは至難の業であり、エラーが発生するまで存在に気付かないケースも多いでしょう。また、不整合データはDFUを用いてもデータ編集できない場合があるため、もし大量のデータの中からそのようなデータを見つけることができても、修正のために別途プログラムを書いて対応するという、手間も時間もかかった対応が求められる場合があります。
②不正な文字
モダナイゼーションを進める上での課題は他にも存在しています。二つ目の例として、「不正な文字」のアプリケーションへの影響を見てみます。この例ではフィールドTKNAKJ(得意先名(漢字))にシフト文字が欠けたデータが登録されています。
データベースのCCSIDが5026(日本語カタカナ)で、ジョブのCCSIDが1399の場合、OSによる暗黙のCCSID変換(5026→1399)が行われます。前掲のプログラムを実行すると、データベースの文字フィールドに不整合データが存在しているため、変換エラーで処理は正しく行われません。
▲SQLでのエラー例
▲RLAでのエラー例
SQL/RLAのいずれのケースでも、プログラムの実行前にコマンド「CHGJOB CCSID(65535)」(65535は「無変換」を示す特殊CCSID)を実行すれば暗黙の変換が抑止され、不整合データが不整合のままプログラムに渡されるのでエラーを回避する事ができます。しかし、Webサービスなどの変換が必要な処理ではエラーの回避は不可能です。
i-T4dbの機能紹介
上記のように、モダナイゼーションを進める上で発生する不整合データに関した困りごとを解決できるのが、冒頭でご紹介した「i-T4db」です。冒頭で述べたように、i-T4dbは主に2つの機能を提供します。
1. CHKPFDTAコマンド
これは物理ファイルのデータ整合性チェックを行う機能です。CHKPFDTAは下記の項目をチェックします。
| 文字フィールド | Aフィールドにシフト文字が存在 |
|---|---|
| シフト文字間に文字が無い | |
| Jフィールドがすべてブランク | |
| シフト文字がペアでない | |
| シフト文字の順序が不正 | |
| 不正な文字(表示不能文字)を検出 | |
| シフト文字の間が奇数 | |
| J/DBCS-Eフィールドの両端に非シフト文字 | |
| 十進フィールド | 非数値データが含まれている |
| 符号が正しくない | |
| パック十進数で最上位ゾーンが不正 |
確認したいデータベース・ファイルやライブラリー、フィールド等データチェック時の条件指定が可能です。また、不整合データを修復またはクリアし、別ライブラリーに複写する(*1)かを選択できます。
*1:軽微な不整合を修復しますが、複合した不整合など自動修復不能なデータがあります。
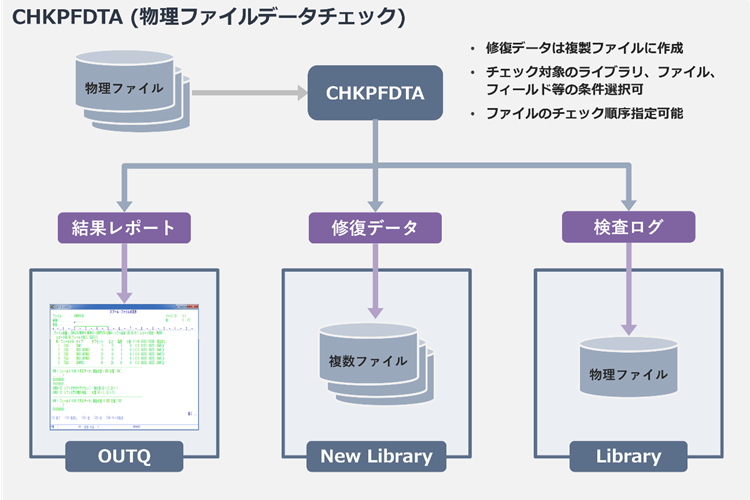
▲CHKPFDTA 出力関係図
上図のようにCHKPFDTAコマンドは3種類の出力を作成します。
1つめの結果レポート出力は、データチェックを行った物理ファイルにどのような不整合データがあったか、それが何桁目であったか、自動修復を行ったか等ログを確認するためのものです。
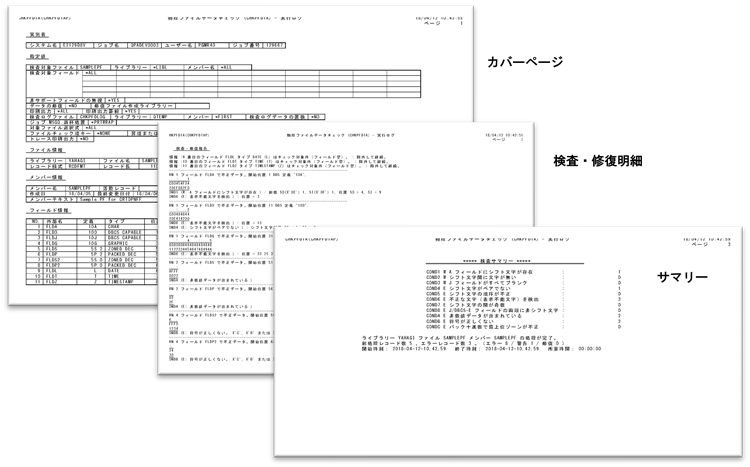
▲結果レポート
2つめの修復データ出力は、CHKPFDTAコマンドで「データの修復」の実施を指定した場合に作成されます。既存データに変更を行わず、新しいライブラリーに修復されたデータを出力します。これにより、意図しないデータ修正を防ぐとともに、修復前後のデータを比較可能としています。
3つめは検査ログのファイル出力です。CHKPFDTAコマンドで「検査ログファイル」を指定した場合に作成され、不整合が検出されたファイル、メンバー、相対レコード番号(RRN)、フィールド、エラー種別などが出力されます。大量の不整合が発生している場合は、このファイルをSQLなどで分析すると効率的です。
CHKPFDTAコマンドを活用すれば、ニーズに合わせて必要なものを選択して効率的にチェックし、データの品質向上が実現できるでしょう。
2. EDTDTA
EDTDTAコマンドは物理ファイルのデータ(レコード)を編集する高機能なデータ編集機能です。
一覧表示・単一レコード表示を自由に切り替えてデータベースレコードを表示・編集できます。既存データの編集に加え、新規レコードの追加や既存レコードの複写、レコードの削除が可能です。
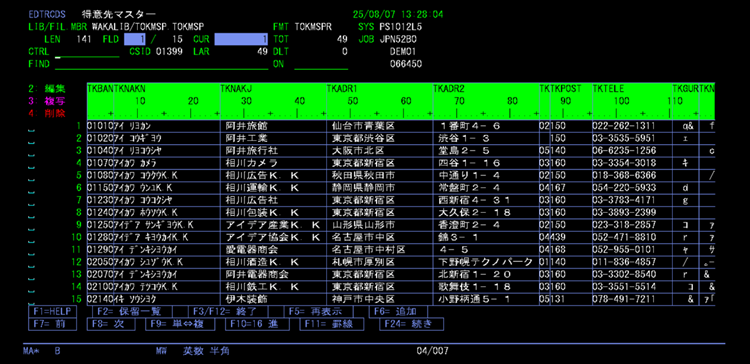
▲EDTDTA 物理ファイル表示例
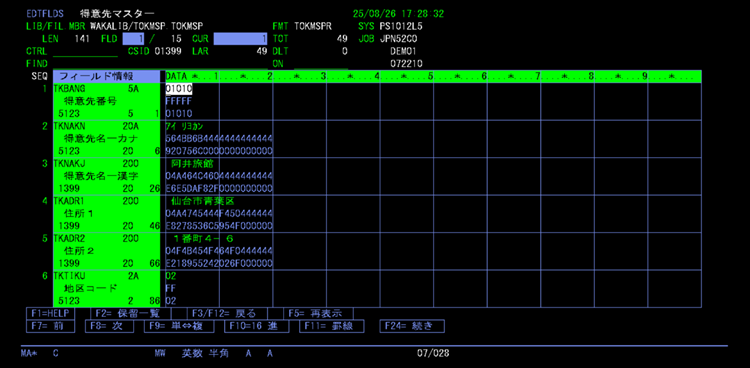
▲EDTDTA 単一表示かつ、16進数表示の画面
EDTDTAコマンドはデータの更新という観点ではDFUと類似していますが、想定される用途は異なります。
| DFU | EDTDTA | |
|---|---|---|
| 主なユーザー | エンドユーザー | 開発者 |
| 画面サイズ | 80桁24行 | 80桁24行/132桁27行 |
| 更新画面上の情報 | 「様式」とデータ | ライブラリー、ファイル、メンバー、レコード件数、CCSID、ジョブ名など |
| データの更新 | 不正データは基本不可。DFUプログラム定義で「エラーの抑制」を指定すれば十進エラーのフィールドを編集可能 | 不正データも含めて文字または16進で直接編集可能 |
| レコード複写 | 不可 | 可能 |
| データの検索 | 不可(キー指定は可能) | 可能(文字、16進指定) |
| 複数レコード表示 | 不可 | 可能 |
| 可変長フィールド | 可能 | 不可 |
| レコードの更新 | 実行キー押下(デフォルトでは「次画面時」も更新) | 複数の変更を保留し、任意の時点で一括更新。保留中の取消し可能 |
| キー順アクセス | 可能 | 不可 |
| 項目の選択/表示形式指定など | DFUアプリケーションで可能 | なし |
| 監査印刷出力 | あり | あり(罫線付加可能) |
| 付加機能 | DFUプログラムの定義の表示(STRDFU画面のみ) | フィールド記述表示、コマンド呼び出し |
| その他 | IBM i 7.6以降正式サポートなし。機能自体は残存 |
i-T4dbの導入メリット
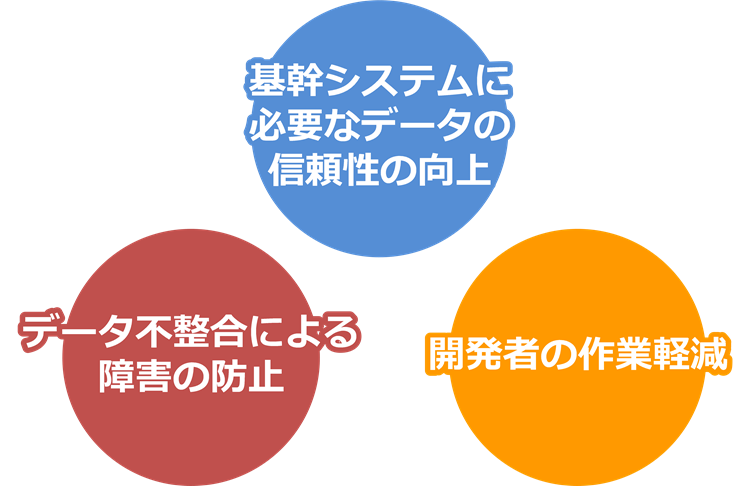
i-T4dbを活用することで得られるメリットとして、主に以下の3点が挙げられます。
1つめは「基幹システムに必要なデータの信頼性の向上」です。
データの信頼性の向上は今後ますます重要になります。DX/モダナイゼーションの推進、サーバー間でのデータ連携実施、JIS2004対応(CCSID1399への移行)による利用可能文字の拡張などは、データが健全である事が前提であり、不整合データの確認をせずにこれらのプロジェクトを実施するのはリスクがあります。i-T4dbを用いてデータチェック・修正を行うことでデータの信頼性を確保して初めて、次のステップへ進むことができるでしょう。
2つめは「データ不整合による障害の防止」です。
前述のとおり、システム内に不整合データが存在すると、コーディングや実行環境によってはプログラム・エラーが発生する場合があります。わずか1レコードのデータ不整合が深刻なアプリケーション障害を引き起こす可能性があり、i-T4dbを用いてデータ不整合の有無を確認・修正すればこのような障害の低減に役立ちます。
3つめは「開発者の作業軽減」です。
データチェックを人間が手作業で行うには限界があります。それが長年運用されているシステムであれば尚更です。i-T4dbは一括でデータの不整合を検出し、レポートやファイルへ出力するので、効率的に作業を行うことができます。データチェックの工数が削減されれば、その分の工数を他のタスクへの割り振るなどの全体最適が図れます。
効率的なモダナイゼーションを目指して
DX/モダナイゼーションを考える上でシステム担当が考えなければならないことは非常に多く、特に人員不足が叫ばれている今、細かなデータチェックを都度行うことは難しいことでしょう。しかし、i-T4dbを使用したデータの整合性チェック・編集を活用することで、少ない人数であっても効率的にモダナイゼーションを進めることができるかもしれません。
前回の寄稿記事である外字を使い続けるために CGU同等機能製品「i-CGU」とはでも触れましたが、ADTSの一部機能廃止によってCGUが使えなくなることは大きな話題となりました。IBM i OS 7.6以降でも外字を使い続けるためには、アイエステクノポートが発売しているi-CGUなどの外字・漢字管理ツールを入れるほか、CCSIDを1399へ移行することで使用可能拡張文字を増やして対応することがあげられます。i-T4dbを利用して不正なデータを洗い出せば、効率的にCCSID1399への移行が進められるでしょう。
今の時代に合ったシステム構築を、IBM iで。そうお考えの方にこそ、弊社はi-T4dbをおすすめいたします。
社内システムのDX推進、モダナイゼーション化を進めるにあたりIBM iのデータチェックを考えたいというお客様は、ぜひ気軽にお問い合わせください。









