データ中心設計
データ中心設計は1970年代初頭に提唱された「情報資源管理」あるいは「データ資源管理」という情報やデータを資源と見なす考え方に端を発していますが、これが一般に広まったのはRDBが普及し始めた1980年代後半、ちょうどAS/400が発表された頃のことです。RDBがごく当たり前の存在となっている現在、データ中心設計はRDB設計の標準的な手法として使用されているので、今更説明するまでもないかもしれません。しかし、その核となる考え方は、データベースのモダナイゼーションを考える上で重要ですので簡単に再確認しておきましょう。 RDBが一般的に使用されるようになる以前のシステム設計は処理プロセスが中心で、処理に必要なデータを提供するためのデータ設計(ファイル設計)という発想で設計されていました。このように各プロセスだけに注目した結果、同じファイルを読み書きするロジックが各処理プログラム中に重複して記述されるという無駄が生じますし、この部分に修正が必要になると、重複部を全て修正しなければなりません。 また、このような設計法ではシステム横断的にデータを捉えることができないため、プロジェクトごとに異なるファイルに同じデータ項目が格納され、それぞれのデータが異なるプログラムで処理されるという状況が発生します。その結果、同じ値を持っているはずの同じデータ項目が、ファイルごとに違う値を持つというデータの不整合が発生します。このような状況でシステムの変更や拡張を行おうとすると、ファイル設計から見直す必要が生じ、その工数が膨大になるという問題があります。 こうした問題の解決策として、システム横断的にデータの設計(つまりデータベース設計)を行い、そのデータを使って処理プロセスの設計を行うデータ中心設計が提唱されました。データ中心設計では「1つの事実は1か所で管理する」という原則の下、データの重複を排除し、かつデータ間の関連性や一貫性などの構造を論理的に整理したうえで、その構造の詳細を隠してデータの本質的な側面だけを見せるようにする点が特徴です。この考え方を更に突き詰めて行くと、データとその操作を一体化させたデータのカプセル化という考え方に至ります(図1)。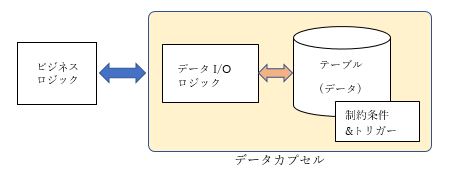 図1.データのカプセル化の概念図
データの生成から消滅に至るデータライフサイクルは、各処理プロセスで制御されるものではなく、本質的にビジネスルールによって制御されるべきものです。ですから、データの挿入、更新、削除に際して適用するべきビジネスルールをデータベースにトリガーとして登録し、データライフサイクルをDBMSの機能で制御するという考え方は、きわめて自然なものと言えます。また、テーブルやテーブル間の関連構造に関する制約条件についても同様のことが言えます。
図1.データのカプセル化の概念図
データの生成から消滅に至るデータライフサイクルは、各処理プロセスで制御されるものではなく、本質的にビジネスルールによって制御されるべきものです。ですから、データの挿入、更新、削除に際して適用するべきビジネスルールをデータベースにトリガーとして登録し、データライフサイクルをDBMSの機能で制御するという考え方は、きわめて自然なものと言えます。また、テーブルやテーブル間の関連構造に関する制約条件についても同様のことが言えます。
DBアクセスロジックのモジュール化
先にも述べたように、今やデータ中心設計はRDB設計の標準的手法ですから、現在使用中のシステムの多くのデータベースはこの考え方に基づいて設計されていると思います。しかし、データの正規化を行い、必要な制約条件を定義してテーブルを作るというのはデータベース設計作業に過ぎません。モダナイゼーションという観点からすると、上述のデータのカプセル化に相当する作業がまだ残っています。 前々回プログラムのモダナイゼーションについて書きましたが、その中でモジュール化とアプリケーション・アーキテクチャの話をしました。アーキテクチャとしてMVCモデルまたは3階層モデルのどちらを採用するにしても、ビジネスロジックからデータベースアクセスを担当する部分を分離して独立した汎用モジュールとして設計し、ビジネスの変化に柔軟に対応できるようにすることが、データベースのモダナイゼーションの目的になります。 DBアクセスモジュールを設計するときに、図1のようにデータI/Oロジックが直接テーブルにアクセスするような構造にすると、テーブルの修正、変更が必要になった場合、同時にデータI/Oロジックの修正も必要になってしまいます。そこで、こうした問題を解消するために、データI/Oロジックとテーブルの間に仮想化レイヤーを挟みます。具体的にはSQLのビューを介してテーブルにアクセスする構造にします。またデータI/Oロジックの変更の影響がこれを呼び出しているモジュール(ビジネスロジック)に波及しないように、DBアクセスモジュールをサービスプログラムとして実装するようにします(図2)。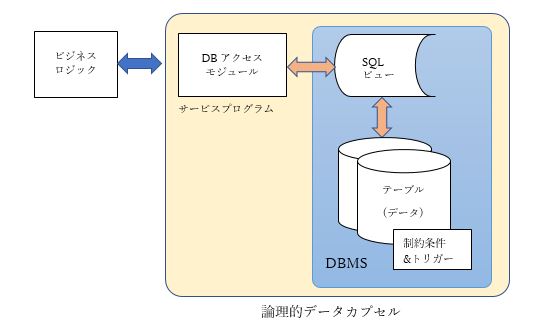 図2.データベースアクセスモジュールの概念図
図2.データベースアクセスモジュールの概念図
データベースのモダナイゼーション手順
データベースのモダナイゼーションの最終目標は図2のようにデータを論理的にカプセル化し、ビジネスロジックとデータアクセスを分離独立させることですが、それにはSQLおよびモジュラー設計/開発技法を習得する必要があり、一足飛びにこのような構造変換を行うことは困難です。そこで、以下のようなステップを踏んでモダナイゼーションを行うのが現実的な方法になります。 実際の実施ステップは現行のデータベース設計がどのようなモダナイゼーション・レベルにあるかによって、どのステップから開始するか変わってきますが、本稿ではシステムの現状は正規化プロセスを踏んでいないDDSで定義されたDBファイルをモノリシックなプログラムでRLAによって処理しているという前提で話を進めます。ステップ1:現状のDDSのDDLへの置き換え
現在のデータの論理構造が正規化されているかどうかはひとまず不問に付し、現行のDDSで定義された物理ファイル(PF)や論理ファイル(LF)を機械的にDDLで定義されたテーブルやインデックスに置き換えます(図3)。このとき、IBM Navigator for iを利用するとDDS定義のDBファイル・オブジェクトからDDLソースを機械的に生成することができます。こうして生成されたDDLソースに必要な修正を加えるようにすれば、作業工数を減らすことができます。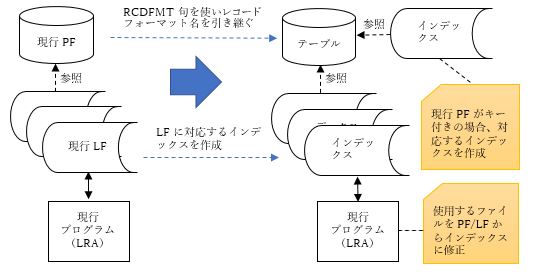 図3.DDSからDDLへの移行(概念図)
現行のプログラムロジックは修正せずに、PFやLFの代わりに新しいテーブル(またはPFのキーに対応するインデックス)やLFに対応するインデックスにアクセスして処理を行うようにソースコードを修正し、プログラムを再コンパイルします。こうすることで、前回説明したようにDBアクセスのパフォーマンスが大きく向上するというメリットを享受できます。
但し、この手法はキー付きの結合論理ファイルや複数フォーマット論理ファイルを使用しているプログラムに対しては使用できません。この場合DDSを使用して現行プログラムを使い続けるという選択肢もありますが、こうしたケースについてはDDLへ完全移行するために、この段階でプログラムをステップ2で説明する結合ビューにSQLでアクセスする形に書き直すべきでしょう。
以上大まかな作業法を示しましたが、ソースコードが存在しない場合には現行プログラムを再コンパイルせずにDDS定義からDDL定義に移行する方法が必要になります。
図3.DDSからDDLへの移行(概念図)
現行のプログラムロジックは修正せずに、PFやLFの代わりに新しいテーブル(またはPFのキーに対応するインデックス)やLFに対応するインデックスにアクセスして処理を行うようにソースコードを修正し、プログラムを再コンパイルします。こうすることで、前回説明したようにDBアクセスのパフォーマンスが大きく向上するというメリットを享受できます。
但し、この手法はキー付きの結合論理ファイルや複数フォーマット論理ファイルを使用しているプログラムに対しては使用できません。この場合DDSを使用して現行プログラムを使い続けるという選択肢もありますが、こうしたケースについてはDDLへ完全移行するために、この段階でプログラムをステップ2で説明する結合ビューにSQLでアクセスする形に書き直すべきでしょう。
以上大まかな作業法を示しましたが、ソースコードが存在しない場合には現行プログラムを再コンパイルせずにDDS定義からDDL定義に移行する方法が必要になります。
ステップ2:データベースの見直しと再構築
現行の概念データモデル(ER図)を作成し、現状のデータの論理構造を把握します。次に、作成した概念データモデルがビジネスの現実と乖離していないか精査し、必要であれば適正な概念データモデルに作り変えます。この概念データモデルに基づいて、RDBMSがデータを適切に管理できるように正規化された論理モデル(ANSI/X3/SPARCの用語では「概念スキーマ」)を設計し、そのDDLを作成します。このとき、テーブル定義には参照制約のようなデータの一貫性を保証するための制約条件も定義します。また、行(レコード)の挿入、更新、削除それぞれの操作に際して行わせたい処理プロセスがあれば、それらをテーブル定義にトリガーとして指定します。 その後、現行のテーブルからデータを移行した新規作成テーブルを使って処理を行います。正規化の影響で複数のテーブルを結合しなければならなくなったプログラムについては、結合ビューを作成しそれをSQLでアクセスするようにロジックを変更します。一方、テーブルの結合が不要なプログラムについては、ステップ1と同様に使用するテーブルに対して必要な インデックスを作成し、現行プログラムを修正せずにRLAのままこれをアクセスします(図4)。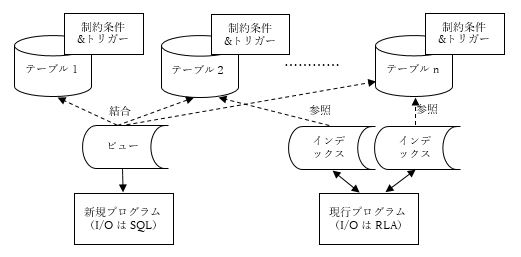 図4.DBの見直しと再構築(概念図)
図4.DBの見直しと再構築(概念図)
ステップ3:DBアクセスロジックの分離独立
アプリケーション・ロジックの中から各テーブルに対してDBアクセスを行っている部分を抽出し、これを独立したDBアクセスモジュール(サービスプログラム)に作り変え、このモジュールを呼び出してDBにアクセスするようにプログラムを修正します。こうすることで、テーブル設計やビジネスロジックに変更が生じても、修正の対象範囲を特定のモジュールに限定することができ、変化に柔軟かつ迅速に対応できるアプリケーション構造にすることができます。また、DBアクセスモジュールは複数のプログラムモジュールで共用できるので、将来の開発工数を削減する効果も期待できます。 DBアクセスモジュールは、SQLで直接目的のテーブルをアクセスするのではなく、ビューを介してアクセスするように設計します。こうすることで、将来テーブル設計の変更が必要になり、複数のテーブルに分解しなければならなくなった場合でも、ビューの修正だけでこれに対応可能な柔軟なアプリケーション構造が出来上がります(図5)。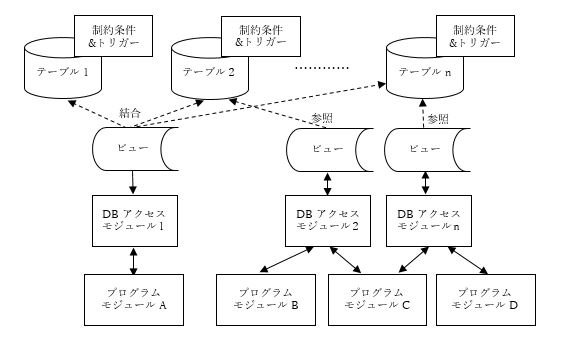 図5.DBアクセスロジックの分離独立(概念図)
図5.DBアクセスロジックの分離独立(概念図)
おわりに
S/38時代から引き継いできたDDS定義によるDBファイル(物理ファイルと論理ファイル)を基礎とするRDBと、データベースに対するRLAはIBM i独自のものです。しかし、今やこの独自機能は20年以上前に作られた当時の「最先端」技術によるアプリケーションを現時点でも使い続けられるようにすることが主要な役割です。 しかし、大量のデータを扱い、そこからビジネスの鍵となるトレンドや知見を得るという現代のデータ活用法を促進するにはSQLへの移行がかかせません。ただ、このDDSの世界からSQLの世界への移行はデータベースのモダナイゼーションの第一歩に過ぎず、これができて初めてモダナイゼーションのスタートラインに立てるのです。 SQLへの移行を果たした上で、モダナイゼーションの最終的な目的である「ビジネス変化への迅速な対応」を可能にするには、データベースとそのアクセス法の設計を見直し、ビジネスロジックとデータ操作を分離独立させるために「データとその操作のカプセル化」を図る必要があります。 つまり、データベースのモダナイゼーションには、まずSQLの世界への移行を行い、次いで「データとその操作のカプセル化」を行うという2つの段階があるわけですが、何はともあれ、第1段階のSQLの世界への移行が喫緊の課題と言えます。 次回はインターフェースのモダナイゼーションについて説明する予定です。どうぞお楽しみに。<著者プロフィール>
西原 裕善(にしはら ひろよし)
日本IBMでSEとしてS/34、S/38のシステム設計および導入作業に従事した後、米国ロチェスターの国際技術支援部門に出向し、全世界のIBM SEやお客様に対してAS/400の技術サポートを行う。帰国後、日本IBM システムズ・エンジニアリング(株)でITアーキテクトとして様々なシステムのアーキテクチャ設計を担当。現在はフリーのテクニカル・ライターとしてIBM iを中心に執筆活動を行っています。