

1. はじめに
前回は、sshでサーバーに接続する場合のクライアント認証の際に、公開鍵認証を実施する方法について解説しました。また、IBM i 側でssh接続のログ収集を行うsyslogの仕組みについても取り上げました。クラウドとの連携が当たり前になっていく中で、クライアントとサーバー間の相互認証の堅牢性と認証後の通信経路の暗号化、そして、接続・切断ログの収集は必須です。IBM i の持つセキュリティー(機密保護)機能と併せて、必ず検討および実施していくようにしましょう。
さて、前回までで、 IBM i を Linux 的に使用するための基礎的な部分の解説は終わりました。
- ssh
- シェル
- 基本コマンド
- パイプとリダイレクト
- RPM と yum
- ファイル転送
- OSS ツールの更新および新規インストール
- vim エディタ
- クライアント認証と syslog
今回からは、上記の解説および設定を前提に、数回に分けてオープンソースで提供される様々なツールを紹介していきます。Linuxユーザーであれば普段から当たり前のように使っているものもあれば、「IBM i ではこういうことが簡単にできるようになるんだ」と新しい発見になるようなツールもあると思います。
読者の皆様が所属している企業ごとに決まりがあり、既にインストールされているツールもあれば、インストールされていないツールもあるはずです。所属企業のルールに基づいて、必要なツールをyumでインストールしてください(第5回「OSS Part-2」を参照)。
それでは始めていきましょう。
2. OSSツールについて
第4回「OSS Part-1」および第5回「OSS Part-2」で解説したように、IBM i にオープンソース環境を構築すると、/QOpenSys/pkgs ディレクトリーに、多くのパッケージがインストールされます。また、IBM i が用意するリポジトリーには、初期導入されたパッケージの更新版や初期インストール時には対象外となる多くのパッケージが用意されています。
確認したところ、2024年11月13日(水)時点で、パッケージの数は「744」でした。全てのパッケージを解説するには、時間も筆者の知識も圧倒的に足りませんので、代表的なものをいくつかピックアップして、独断と偏見に基づくグループに分類して紹介していきます。
圧縮・解凍
| 名称 | パッケージ名 |
|---|---|
| tar | tar-gnu.ppc64 |
| gzip / unzip | zip.ppc64 / unzip.ppc64 |
| bzip2 | bzip2.ppc64 |
| p7zip | p7zip.ppc64 |
圧縮・解凍の各ツールについては別の章で解説します。
開発ツール
| 名称 | パッケージ名 | 説明 |
|---|---|---|
| git | tar-gnu.ppc6git.ppc644 | Version Control System |
| make | make-gnu.ppc64 | プログラムのコンパイル(ビルド)作業を自動化するツール |
| bob | bob.ppc64 | Better Object Builder for IBM i |
gitは言わずと知れたソース・コードのバージョン管理システムです。通常は、ソース・コードをクライアントに置いて修正などの作業を行い、クライアントにインストールしたgitでバージョンを管理します。このgitをIBM i にインストールすることで、IBM i 環境でも同様の操作が行えるようになります。
makeは、Linux等で使われているビルド作業を自動化するツールです。ソース・コードで配布されるUNIX / Linux系のソフトウェアの場合、ビルドする際にはmakeが使われることが大半です。
bobは、IBM i 固有のツールであり、プログラムやサービス・プログラムといった IBM i 特有のオブジェクトのコンパイルを可能にします。オブジェクトの依存関係を事前に記述しておくことで、サービス・プログラムをコンパイルする際に、オブジェクトを参照するプログラムも一緒にコンパイルするといった設定も可能です。bobはmakeを使用するので、依存関係の記述方法はmakeと同様です。gitと組み合わせることにより、本番環境への自動リリース(デプロイ)などがある程度可能になるので、将来的には手作業のリリース作業が必要なくなる日が来るかもしれません。
Web系ツール
| 名称 | パッケージ名 | 説明 |
|---|---|---|
| curl | curl.ppc64 | インターネット転送エンジン |
| jq | jq.ppc64 | jsonデータ処理 |
| wget | wget.ppc64 | Webサイト経由でファイルをダウンロード |
| openssh | openssh.ppc64 | sshのオープンソース実装 |
| nginx | nginx.ppc64 | Webサーバー |
| lftp | lftp.ppc64 | ファイル転送(第6回「ファイル転送」参照) |
curlとjqについては、別の章で解説します。
wgetは、指定したURLからファイルをダウンロードします。アクセスするURLによってはhtmlファイル等を取得することも可能です。一般的には、http(s)プロトコルで配布されているファイルを取得するために使用します。
下記は、RPGのマニュアルをダウンロードしています。
-bash-5.1$ wget https://www.ibm.com/docs/ssw_ibm_i_72/rzasd/sc092508.pdf
nginxは、Webサーバー・アプリケーションです。IBM i は、標準Webサーバーとして利用可能なapacheと同様にnginxも使用できます。
IBM i Access
| 名称 | パッケージ名 | 説明 |
|---|---|---|
| unixODBC | unixODBC.ppc64 | ODBCドライバー・マネージャー |
| ibm-iaccess | ibm-iaccess.ppc64 | IBM i 用ODBCドライバー |
IBM i のデータベースにODBCで接続するために必要なパッケージです。別の章で解説します。
テキスト処理
| 名称 | パッケージ名 | 説明 |
|---|---|---|
| grep | grep-gnu.ppc64 | ファイルの行検索 |
| sed | sed-gnu.ppc64 | Stream Editor / コマンドベースでテキストを編集 |
| awk | gawk.ppc64 | テキスト・ファイルを処理するプログラミング言語 |
| iconv | iconv-gnu.ppc64 | 文字コード変換 |
| vim | vim.ppc64 | テキスト・エディタ(第5回「OSS Part-2」参照) |
テキスト処理については、今後執筆予定の「OSS ツール Part-2」で取り上げます。
その他
| 名称 | パッケージ名 | 説明 |
|---|---|---|
| ibmichroot | ibmichroot.noarch | chrootのIBM i IFS版 |
| ncdu | ncdu.ppc64 | ディスク使用量確認 |
| tree | tree.ppc64 | ディレクトリー構造の表示 |
上記の3つのツールは、今後執筆予定の「OSS ツール Part-3」で取り上げます。
3. 圧縮・解凍
それでは、圧縮・解凍の各ツールの解説から始めます。
tar + gzip / bzip2
圧縮とは、対象のファイルのサイズをあるルールに基づいて小さくすることですが、一般的には複数のファイルをひとつにまとめるアーカイブ処理も含んでいます。Linuxでよく使われている圧縮は、もともと以下の手順で行われていました。
- 1つあるいは複数のファイルをアーカイブ(tar)
- アーカイブしたファイルを圧縮(gzip / bzip2)
tarは、Windowsユーザーにはあまり馴染みがないツールですね。Linux系OSのソフトウェアは、tar形式にアーカイブして配布されることが多いです。IBM i のオープンソース環境導入時にも、/tmpディレクトリにbootstrap.tar.Z(拡張子 .tar.Z は tar でアーカイブしたものを圧縮したと想定される)ファイルをダウンロードし、ダウンロードしたbootstrap.tar.Zを解凍して導入が行われました(第4回「OSS Part-1」の「導入の裏側」参照)。
では、IBM i における、tar + gzipを使用した圧縮の例を見てみましょう。
ディレクトリー「./test」を、ファイル「test.tar」にアーカイブし、アーカイブしたファイルを圧縮して「test.tar.gz」を作成する手順は、以下の通りです。
-bash-5.1$ tar -cvf test.tar ./test ./test/ ./test/rcvdtaq.rpgle ./test/snddtaq.rpgle : ./test/.vscode/ ./test/.vscode/actions.json -bash-5.1$ gzip ./test.tar
tar コマンドでは、ハイフンに続いて3つのオプションを指定していますが、それぞれの意味は以下の通りです。
- c = 新しいアーカイブを作成
- v = 処理したファイルの情報を出力
- f = アーカイブ・ファイル名を指定
この例では、ディレクトリー「./test」以下の全ファイルを、「test.tar」という名称のファイルにtarコマンドでアーカイブ後、 gzipコマンドで圧縮しました。gzipで圧縮したファイルの名前は「test.tar.gz」です。元のアーカイブ・ファイルを上書きして作成されます。
現在は、tarコマンドのオプションで圧縮形式の指定が可能なので、tar + gzip / bzip2で作成する例は一般的ではないかもしれません。
tarコマンドでアーカイブすると同時にgzipで圧縮するには、オプションで「z」を指定します(bzip2を使用する場合はオプションで「j」を指定)。
-bash-5.1$ tar -zcvf test.tgz ./test ./test/ ./test/rcvdtaq.rpgle ./test/snddtaq.rpgle : ./test/.vscode/ ./test/.vscode/actions.json -bash-5.1$
解凍は以下のように指定します。
-bash-5.1$ tar -zxvf test.tgz ./test/ ./test/rcvdtaq.rpgle ./test/snddtaq.rpgle : ./test/.vscode/ ./test/.vscode/actions.json -bash-5.1$
上記でお分かりいただけると思いますが、ファイルを取り出す(解凍する)際は、オプションで「x」を指定します。
tar + gzipの圧縮は、最初に1つあるいは複数のファイルのアーカイブを行い、その後アーカイブ・ファイルを圧縮しています。そのため、個々のファイルを個別に圧縮されたファイルからは取り出せません。この点に注意してください。
zip / unzip
zip / unzipは、「ファイルの圧縮・アーカイブ」と「解凍」とをそれぞれ実行します。圧縮時は、
- 個々のファイルを圧縮
- 圧縮した1つあるいは複数のファイルをアーカイブ
という手順で行われます。tar + gzipと異なり、先に圧縮処理をした1つあるいは複数のファイルをアーカイブしているので、個々のファイルを個別に取り出すことが可能です。
zipは、Windowsでも標準で利用可能なので、一番扱いやすい圧縮ツールかもしれません。
-bash-5.1$ zip -r test.zip ./test adding: test/ (stored 0%) adding: test/rcvdtaq.rpgle (deflated 73%) adding: test/snddtaq.rpgle (deflated 67%) : adding: test/Q842SRC/commd.rpgle (deflated 35%) adding: test/.vscode/ (stored 0%) adding: test/.vscode/actions.json (deflated 82%) -bash-5.1$
解凍には、unzipを使います。
-bash-5.1$ unzip test.zip :
パスワード付きで圧縮するには、–password=xxxxxxxx で指定します。
-bash-5.1$ zip -r --password=xxxxxxxx test.zip ./test adding: test/ (stored 0%) adding: test/rcvdtaq.rpgle (deflated 73%) adding: test/snddtaq.rpgle (deflated 67%) : adding: test/Q842SRC/commd.rpgle (deflated 35%) adding: test/.vscode/ (stored 0%) adding: test/.vscode/actions.json (deflated 82%) -bash-5.1$
解凍する場合は、パスワードの入力が求められます。
-bash-5.1$ unzip test.zip Archive: test.zip creating: test/ [test.zip] test/rcvdtaq.rpgle password: :
7-Zip
複数のプラットフォームで利用可能なzipは便利である一方、アーカイブの合計サイズなどが最大4GBという制限があります。一般的には4GBで問題ありませんが、IBM i の保管ファイルや仮想テープ装置項目などは4GBを超えるファイルが存在する可能性があります。
4GBを超えるファイルを圧縮する場合は、7-Zipを使用します。アーカイブにファイルを追加するには、オプション「a」を指定してください。
-bash-5.1$ 7z a -mx=5 SF99652_1.7z SF99652_1.bin 7-Zip 16.02 : Copyright (c) 1999-2016 Igor Pavlov : 2016-05-21 p7zip Version 16.02 (locale=JA_JP.UTF-8,Utf16=on,HugeFiles=on,64 bits,1 CPU BE) Scanning the drive: 1 file, 4241489920 bytes (4045 MiB) Creating archive: SF99652_1.7z Items to compress: 1 9% + SF99652_1.bin
今回は a -mx=5 を指定していますが、これは圧縮レベルが標準であることを示しています。
今回対象としたファイルは、IBM i の累積PTF の光ディスク・イメージ・ファイルで、元のサイズは 4,241,489,920 バイトでした。圧縮レベルを4パターン実行して、かかった時間と圧縮後のサイズを比較した表が以下です。
| 圧縮レベル | 圧縮時間 | 圧縮後サイズ | 圧縮率 |
|---|---|---|---|
| 0(無圧縮) | 1分43秒 | 4,241,490,050 | 100.0% |
| 1 | 14分03秒 | 2,776,065,561 | 65.5% |
| 5 | 30分42秒 | 2,390,703,727 | 56.3% |
| 9 | 44分33秒 | 2,348,446,534 | 55.3% |
圧縮にかかった時間はマシン構成によっても異なるので、あくまでも圧縮レベル間での比較の目安として使用してください。また、7-Zip コマンドは、CPU の使用率が非常に高いので、コマンドを実行する時間には注意してください。
7-Zip でパスワードを設定するには、-p に続けてパスワードを指定します。
-bash-5.1$ 7z a -pxxxxxxxx test.7z ./test 7-Zip 16.02 : Copyright (c) 1999-2016 Igor Pavlov : 2016-05-21 p7zip Version 16.02 (locale=JA_JP.UTF-8,Utf16=on,HugeFiles=on,64 bits,1 CPU BE) Scanning the drive: 3 folders, 20 files, 13493 bytes (14 KiB) Creating archive: test.7z Items to compress: 23 Files read from disk: 20 Archive size: 2607 bytes (3 KiB) Everything is Ok -bash-5.1$
解凍するにはオプション x を指定します。パスワードの入力が求められます。
-bash-5.1$ 7z x test.7z 7-Zip 16.02 : Copyright (c) 1999-2016 Igor Pavlov : 2016-05-21 p7zip Version 16.02 (locale=JA_JP.UTF-8,Utf16=on,HugeFiles=on,64 bits,1 CPU BE) Scanning the drive for archives: 1 file, 2607 bytes (3 KiB) Extracting archive: test.7z -- Path = test.7z Type = 7z Physical Size = 2607 Headers Size = 559 Method = LZMA2:14 7zAES Solid = + Blocks = 1 Enter password (will not be echoed): Everything is Ok Folders: 3 Files: 20 Size: 13493 Compressed: 2607 -bash-5.1$
圧縮・解凍に使用するツールは複数ありますので、適材適所で使い分けるようにしてください。
4. curlとjq
次に、業務よりの処理に利用可能なツールを紹介しましょう。クラウドからjson形式でデータを取得して、IBM i のデータベースにデータを登録するまでをOSSツールとsshコマンドで実行します。
処理フロー
想定する基本的な処理フローは以下の通りです。
- Web APIを使用して、クラウドのサーバーからjson形式でファイルを取得する
- json形式のファイルをCSV形式に変換してIFSに保存する
- IBM i のコマンドをsshから呼び出して、CSVファイルをデータベースに登録する
という手順で行われます。tar + gzipと異なり、先に圧縮処理をした1つあるいは複数のファイルをアーカイブしているので、個々のファイルを個別に取り出すことが可能です。
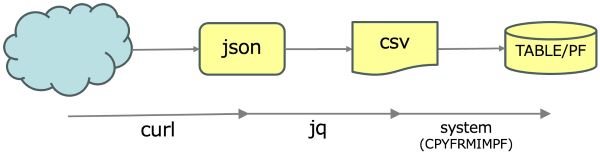
jsonデータはクラウド・サービス「HeartRails Express」から取得します。このサービスを使えば、全国の路線および県名のデータをWeb APIを経由してjson形式で取得できます。
では、山手線の駅名を json 形式で取得し、データベース・ファイルに書き出してみましょう。リクエストURLとパラメーターは「駅情報API」に詳細があるので、興味のある方は参照してください。
今回は、以下のURLでデータを取得します。
http://express.heartrails.com/api/json?method=getStations&line=JR山手線
上記URLにブラウザー(Chrome の場合)からアクセスすると、以下のようにjsonデータが表示されます。
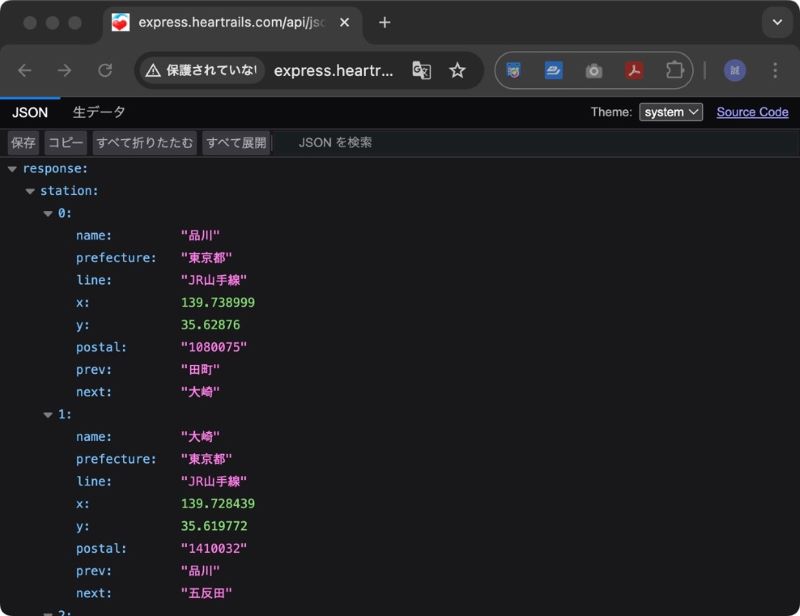
実際のjsonデータは以下の通りです。
{
"response": {
"station": [
{
"name": "品川",
"prefecture": "東京都",
"line": "JR山手線",
"x": 139.738999,
"y": 35.62876,
"postal": "1080075",
"prev": "田町",
"next": "大崎"
},
:
{
"name": "高輪ゲートウェイ",
"prefecture": "東京都",
"line": "JR山手線",
"x": 139.740651,
"y": 35.635476,
"postal": "1080075",
"prev": "田町",
"next": null
}
]
}
}
ここで少し、jsonの構造について解説します。まず、jsonファイルには、プロパティ、オブジェクトという概念があります。
プロパティはデータそのもので、キー名とその値を「:(コロン)」で区切って表現します。そして、この1つあるいは複数のプロパティを中括弧 { } で囲んでグループ化したものをオブジェクトといいます。
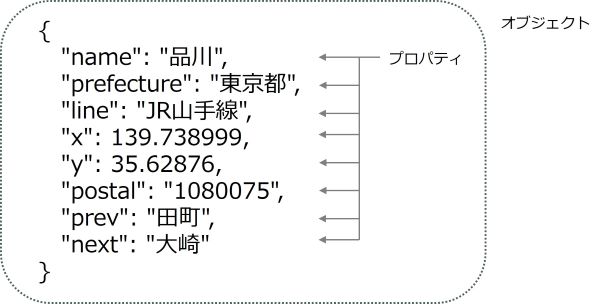
また、jsonは配列を角括弧 [ ] で区切って表現します。プロパティの値を配列にすることも、オブジェクトを配列にすることも可能です。
では、今回のjsonデータの構造を見てみましょう。山手線の各駅の複数のプロパティをまとめたオブジェクト(30オブジェクト)が、「station」配列に格納され、それを「response」という名前のオブジェクトでまとめています。
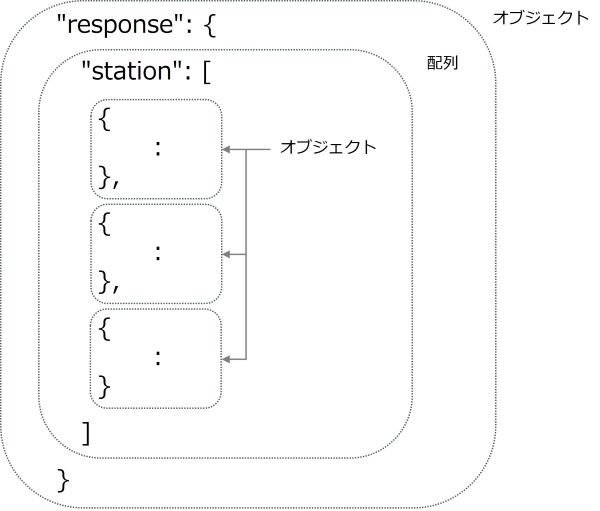
実際のデータは、responseオブジェクト全体を、さらに中括弧で囲っています。
では、駅ごとのプロパティを見てみましょう。
{
"name": "品川",
"prefecture": "東京都",
"line": "JR山手線",
"x": 139.738999,
"y": 35.62876,
"postal": "1080075",
"prev": "田町",
"next": "大崎"
}
上記は、品川駅のプロパティをまとめたオブジェクトです。各キーとその値は以下の通りです。
| No. | 項目名 | 値 | 補足 |
|---|---|---|---|
| 1 | name | 品川 | 対象駅名 |
| 2 | prefecture | 東京都 | |
| 3 | line | JR山手線 | |
| 4 | x | 139.738999 | 経度 |
| 5 | y | 35.62876 | 緯度 |
| 6 | postal | 1080075 | |
| 7 | prev | 田町 | 前の駅名 |
| 8 | next | 大崎 | 次の駅名 |
上記値のうち、nameとprevおよびnextの値を取り出して、データベースに格納していきます。
curl
それでは、上記のjsonデータをOSSツールを使って取得してみましょう。使用するのはcurlです。記述は簡単で、curlに続けてアクセスするURLを指定します。今回はリクエスト・パラメーターに漢字を含んでいるので、URL全体を引用符で囲ってください。実行結果は以下の通りです。
4GBを超えるファイルを圧縮する場合は、7-Zipを使用します。アーカイブにファイルを追加するには、オプション「a」を指定してください。
-bash-5.1$ curl 'http://express.heartrails.com/api/json?method=getStations&line=JR山手線'
{"response":{"station":[{"name":"品川","prefecture":"東京都","line":"JR山手
線","x":139.738999,"y":35.62876,"postal":"1080075","prev":"田町","next":"大崎"},
{"name":"大崎","prefecture":"東京都","line":"JR山手線","x":139.728439,"y":35.619772,"postal":"1410032",
"prev":"品川","next":"五反田"},{"name":"五反田","prefecture":"東京都","line":"JR山手線",
"x":139.723822,"y":35.625974,"postal":"1410022","prev":"大崎","next":"目黒"},
{"name":"目黒","prefecture":"東京都","line":"JR山手線",
"x":139.715775,"y":35.633923,"postal":"1410021","prev":"五反田","next":"恵比寿"}],
:
取得したjsonデータが画面に表示されましたか?
上記は正しく取得できた例ですが、適切な改行がされてないのでデータとしては読みにくいと思います。これを、先ほどのサンプルのように、きれいに整形して表示してみましょう。
jq
jsonデータの処理には jq を使用します。jq を使えば json の様々な操作および整形を行うことができます。
jsonデータを見やすい形に整形するには、取得したjsonデータをパイプ処理でjqに渡します。
-bash-5.1$ curl 'http://express.heartrails.com/api/json?method=getStations&line=JR山手線' | jq
{
"response": {
"station": [
{
"name": "品川",
"prefecture": "東京都",
"line": "JR山手線",
"x": 139.738999,
"y": 35.62876,
"postal": "1080075",
"prev": "田町",
"next": "大崎"
},
:
{
"name": "高輪ゲートウェイ",
"prefecture": "東京都",
"line": "JR山手線",
"x": 139.740651,
"y": 35.635476,
"postal": "1080075",
"prev": "田町",
"next": null
}
]
}
}
次に、30ある駅情報のみを抜き出してみましょう。先ほどの構造の説明を思い出してください。駅情報はjsonデータ内のresponseオブジェクトに格納されたstation配列に入っています。今回必要なのはstation配列なので、station配列だけを取り出すフィルターを指定します。実際のフィルターは以下の通りです。
'.response.station[]'
このフィルターの意味は、
- json本体( . )の
- responseオブジェクトに含まれる
- station配列
を対象にするということです(先ほどの json の構造を思い出してください)。
では、このフィルターを指定した jq を実行してみましょう。
-bash-5.1$ curl 'http://express.heartrails.com/api/json?method=getStations&line=JR山手線' | jq '.response.station[]'
{
"name": "品川",
"prefecture": "東京都",
"line": "JR山手線",
"x": 139.738999,
"y": 35.62876,
"postal": "1080075",
"prev": "田町",
"next": "大崎"
}
:
{
"name": "高輪ゲートウェイ",
"prefecture": "東京都",
"line": "JR山手線",
"x": 139.740651,
"y": 35.635476,
"postal": "1080075",
"prev": "田町",
"next": null
}
続いて、上記の各駅の情報のうち、name、prev および next の3つの値を配列形式で取り出します。
jq '.response.station[] | [.name, .prev, .next]
-bash-5.1$ curl 'http://express.heartrails.com/api/json?method=getStations&line=JR山手線' \ | jq '.response.station[] | [.name, .prev, .next]' [ "品川", "田町", "大崎" ] [ "大崎", "品川", "五反田" ] : [ "高輪ゲートウェイ", "田町", null ]
必要な値だけを抜き出すことができました。
これを、CSV形式に変換します。上記で配列化したものを、さらにパイプで @csv(フィルター関数)に渡してcsv形式に変換します。@csvに渡す際は純粋なデータのみを渡したいので、「–raw-output」オプションも同時に指定しています。
-bash-5.1$ curl 'http://express.heartrails.com/api/json?method=getStations&line=JR山手線' \ | jq --raw-output '.response.station[] | [.name, .prev, .next] | @csv' "品川","田町","大崎" "大崎","品川","五反田" "五反田","大崎","目黒" "目黒","五反田","恵比寿" : "浜松町","新橋","田町" "田町","浜松町","品川" "高輪ゲートウェイ","田町",
curlとjqを組み合わせることで、jsonから必要な情報のみを抜き出してCSV形式にできました。これをリダイレクトして、IFSに「sattionp.csv」という名前のCSVファイルで保存します。
-bash-5.1$ ls -l
total 0
-bash-5.1$ curl 'http://express.heartrails.com/api/json?method=getStations&line=JR山手線' \
| jq --raw-output '.response.station[] | [.name, .prev, .next] | @csv' > stationp.csv
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 4484 100 4484 0 0 35307 0 --:--:-- --:--:-- --:--:-- 35587
-bash-5.1$ ls -l
total 8
-rw-r--r-- 1 ogawa 0 1184 Nov 15 10:13 stationp.csv
system ‘CPYFRMIMPF …’
では、IFSに出力したstationp.csvのデータを、IBM i の物理ファイル(テーブル)にコピーしましょう。今回は、IBM i の CPYFRMIMPFコマンドを使用します。
今回は、あらかじめ以下のDDLで作成したファイル「STATIONP」を使用します(もちろん、CRTPFで作成しても構いません)。
CREATE TABLE OGAWA.STATIONP ( NAME CHAR(20) CCSID 1399 NOT NULL DEFAULT '' , PREV CHAR(20) CCSID 1399 NOT NULL DEFAULT '' , NEXT CHAR(20) CCSID 1399 NOT NULL DEFAULT '' ) RCDFMT STATIONPR ;
CPYFRMIMPF は以下のように記述します。
CPYFRMIMPF FROMSTMF("/home/OGAWA/stationp.csv") TOFILE(OGAWA/STATIONP) RCDDLM(*LF) RPLNULLVAL(*FLDDFT)
コマンドの各パラメーターの意味は以下の通りです。
| パラメータ | 値 | 意味 |
|---|---|---|
| FROMSTMF | /home/OGAWA/stationp.csv | コピー元のCSVファイルのパス名 |
| TOFILE | OGAWA/STATIONP | コピー先のIBM i のテーブル(物理ファイル)名 |
| RCDDLM | *LF | CSVファイルの改行コード |
| RPLNULLVAL | *FLDDFT | 値がヌルの場合はフィールドの省略値を使用 |
では、コピーを実行してみましょう。
-bash-5.1$ system 'CPYFRMIMPF FROMSTMF("/home/OGAWA/stationp.csv") TOFILE(OGAWA/STATIONP) RCDDLM(*LF) RPLNULLVAL(*FLDDFT)'
CPC2959: 30レコードがメンバーSTATIONPにコピーされました。
コピーされたことが確認できました。
5. unixODBCとibm-iaccess
データベースに登録されたデータの確認には、SQLのSELECT文を使いたいですね。IBM i でSQLを実行する方法は以下の3通りです。
- 5250画面にてSTRSQLを実行
- Access Client Solutionsの「SQLスクリプトの実行」を使用
- unixODBCのisqlを使用
今回はssh接続後にSQLを実行したいので、3の方法で行います。
sshで接続したセッションから、外部のデータベースにODBC接続で行うのが簡単です。これを実現するには、unixODBCドライバ・マネージャが必要です。さらに、IBM i のデータベースにアクセスするには、IBM i 用のODBCドライバーであるibm-iaccessも必要です。もしibm-iaccessが導入されていなければACS経由、もしくは、yumコマンドでインストールしておきましょう。
yum install unixODBC ibm-iaccess
では、isqlコマンドを使用して、IBM i のデータベースに接続します。
-bash-5.1$ isql *local +---------------------------------------+ | Connected! | | | | sql-statement | | help [tablename] | | quit | | | +---------------------------------------+ SQL>
sshで接続したIBM i のデータベースに接続が完了すると、プロンプトが「SQL> 」と表示されます。では、SELECT文を実行して、データが正しく登録されているかを確認してみましょう。
SQL> select * from ogawa.stationp +-------------------+--------------------------+--------------------------+ | NAME | PREV | NEXT | +-------------------+--------------------------+--------------------------+ | 品川 | 田町 | 大崎 | | 大崎 | 品川 | 五反田 | : | 浜松町 | 新橋 | 田町 | | 田町 | 浜松町 | 品川 | | 高輪ゲートウェイ | 田町 | | +-------------------+-------------------------+---------------------------+ SQLRowCount returns -1 30 rows fetched SQL>
先ほど、CPYFRMIMPFコマンドでコピーしたテーブル(物理ファイル)のデータを確認できました。
isqlを終了する際には、quitを実行しましょう。
SQL> quit -bash-5.1$
前章で解説した、クラウドから json を取得し SELECT でデータを確認するまでに実行したコマンドを以下にまとめておきます。
jsonを取得して、csv形式のファイルに変換して保管
-bash-5.1$ curl 'http://express.heartrails.com/api/json?method=getStations&line=JR山手線' \ | jq --raw-output '.response.station[] | [.name, .prev, .next] | @csv' > stationp.csv
csvファイルをテーブル(物理ファイル)にコピー
-bash-5.1$ system 'CPYFRMIMPF FROMSTMF("/home/OGAWA/stationp.csv") TOFILE(OGAWA/STATIONP) RCDDLM(*LF) RPLNULLVAL(*FLDDFT)'
IBM i のデータベースに接続
-bash-5.1$ isql *local
6. おわりに
今回は、「OSS ツール Part-1」と題して、様々な圧縮・解凍ツール、外部連携に必要なツールを紹介しました。また、ODBC経由でSQLを実行するために必要なOSSパッケージとその基本的な使用方法も紹介しました。
特に、curlとjqで紹介したサンプルは、Linuxユーザーにはお馴染みですが、IBM i ユーザーの皆様には「こんなこともできるんだ」という新たな発見があったのではないでしょうか。
同様のことをIBM i で行おうとすると、以下のような方法で実装されることが一般的に多いはずです。
- SYSTOOLS.HTTPGETCLOB関数等をSQLから呼び出してjsonデータを取得
- JSON_TABLE関数でデータを整形
- 整形後のデータをINSERT文でテーブル(物理ファイル)に追加
これらのSQL文はそれなりに複雑になるので、一般的にはSQLを組み込んだRPG等を作成することになると思います。SQLが複雑で、更にプログラミング(コンパイル)も必要となると、気軽に試してみるというわけにはいかなくなりますね。
一方、curlとjqを使えば、簡単にjsonデータの取得および整形とデータベース化が行えることがお分かりいただけたと思います(たった2行です!)。また、OSSのコマンドの出力結果を他のコマンドの入力にするパイプ処理の便利さを改めて感じていただけたことでしょう。
今後もパイプおよびリダイレクト処理が頻繁に出てきますので、必要に応じて第3回「シェルと基本コマンド」を参照ください。
次回は、テキスト・ファイルを処理するための様々なツールを扱う予定です。それでは、次回をお楽しみに!
参考文献
- @IT『【 tar 】コマンド――アーカイブファイルを作成する/展開する』
- ウィキペディア『# make (UNIX)』
- Medium『jq コマンドで JSON を CSV に変換する』
- ./jq『# jq 1.6 Manual』
- DevelopersIO『軽量JSONパーサー『jq』のドキュメント:『jq Manual』をざっくり日本語訳してみました』
- SEIDEN GROUP.『# Using Yum to Install or Update the IBM i ODBC Driver』












連載第8回では、オープンソースで提供される様々なツールを紹介する第1回として、「圧縮・回答ツール」と「業務よりの処理に利用可能なツール」を紹介します。(編集部)