

2025年11月13日 アダム・シェディヴィ、デヴァンシュ・クマール
数十年もの間、IBM i上にある情報へのアクセスには専門知識が必要でした。専門知識とは、具体的には、SQLに精通していることや、システム・ビューとサービスに関する深い知識、コマンドライン操作を熟知していること、などを指します。例えば、システム・セキュリティーを確認する必要がある場合には、複数のQSYS2ビューにまたがるクエリーを作成する必要があります。パフォーマンスのトラブルシューティングを実施する場合は、さまざまなシステム・サービスに対してSQL文を作成し、その結果を分析することになるでしょう。
このような専門知識を身につけていることは強みとなりますが、補完的な方法によってシステムと対話できるとしたらどうでしょうか?
平易な自然言語を用いて、使用しているシステムに質問するだけで、実施可能な回答が得られると想像してみてください。セキュリティー上の懸念を調査するにあたり、「完全なセキュリティー監査を実行してください」と指示するだけで、システムが自動的に関連するビューをクエリーし、データを分析し、結論を提示してくれるとしたらどうでしょうか?パフォーマンスのトラブルシューティングにあたり、システムが自動的に原因を判断してくれるようになり、どのSQLサービスをクエリーするべきかを覚えておく必要がなくなったとしたらどうでしょうか?
これは、もはや、SFではありません。現在、AIエージェントは上述したようなことを実現しており、企業や組織はIBM iとやり取りする方法を変革しようとしています。IBM iに関わる人々にとって、AIエージェントが特にエキサイティングな理由は、IBM iがエージェント・ネイティブなオペレーティング・システムとして初めて登場するという、独自の立場にあるからです。
「AIエージェント対応」となるために、複雑なミドルウェアやカスタムAPIが必要となる他のプラットフォームとは異なり、IBM iのアーキテクチャーは本質的に「AIエージェント対応」へ移行の準備ができています。IBM iは、Db2 for iとの数十年にわたる緊密な統合と、包括的なSQLサービスのおかげで、セキュリティー設定からパフォーマンス指標、ジョブ管理に至るまで、事実上全てのシステム属性をSQL経由でクエリーすることも制御することも、すでに可能になっています。この「SQLをコントロール・プレーンとして使用する」設計により、長年にわたって構築、テスト、改良されてきた単一の標準化されたインターフェースたるSQLを通じて、AIエージェントはIBM iと連携できるのです。
これはIBM iのコミュニティーにとって、またとない機会です。他のプラットフォームが、AIエージェント互換インターフェースをゼロから構築するのに対して、IBM iを使用している企業や組織は、成熟したSQLを活用してAIエージェントを即座に導入できます。数十年前に行われたアーキテクチャー上の決定(当時、純粋に「実用的」と判断された決定)が、今やIBM iをエージェント型AI革命の最前線に位置付けているのです。
システム管理に使用してきたSQLが、今や対話型AIインターフェースの基盤になっています。インフラストラクチャーは、すでに整っています。ツールは成熟しています。アクセスパターンも実証済みです。
AIエージェントとは何か、AIエージェントはどのように機能するのか、IBM i環境においてAIエージェントは具体的にどのような意味を持つのか、そして、なぜIBM iはエージェント・ネイティブなオペレーティング・システムとしての準備ができているのかを探ってみましょう。
基本的な構成要素
AIエージェントの核となるのは、ChatGPTやClaudeなどのツールと同じ技術である大規模言語モデル(LLM)です。しかし、チャットボットとAIエージェントの間には、決定的な違いがあります。
チャットボットは会話しかできません。チャットボットは、トレーニング中に学習したパターンに基づいてテキストを生成します。「今日の天気はどうですか?」と尋ねると、季節のパターンに基づいて推測を行うかもしれませんが、実際に天気を確認することはできません。
AIエージェントはアクションを起こせます。AIエージェントは、機能拡張で強化されたLLMであり、実際にアクションを起こし、ユーザーに代わって現実の情報を収集することが可能です。
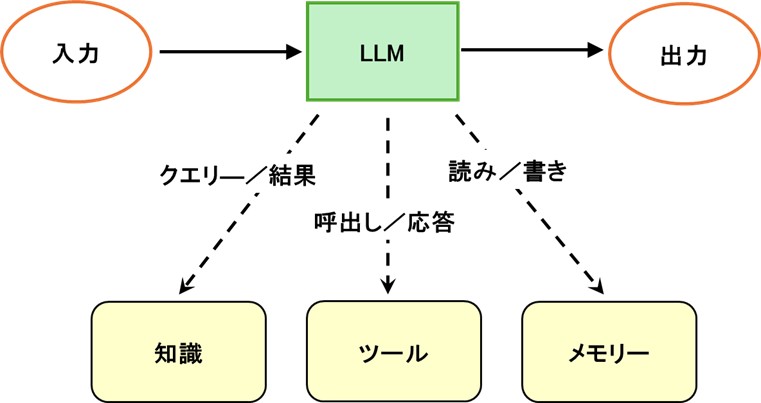
図1. LLMは、知識、ツール、メモリーを用いてアクションを起こします。
これらの機能拡張は、必要に応じて利用できる「ツール」をAIに与えるものと考えてください。そして、「ツール」には、カスタム検索クエリーから、データベース接続、システムに関するドメイン固有の知識まで、あらゆるものがあります。これらの機能拡張は、AIモデルを単なるテキスト生成ツールから、タスクを実行できる能動的なアシスタントに変換します。
それぞれの機能拡張を詳しく見てみましょう。
- 知識
外部ソースから情報をクエリーし、取得する能力。AIエージェントはトレーニングデータのみに依存せず、データベースや参照文献、またはウェブサイトを検索して、最新かつ正確な情報を取得します。 - ツール
アクションの実行、コマンドの実行、SQLクエリーの実行、APIの呼び出し、外部システムとの連携などを行う能力。ツールにより、LLMを単なるテキスト生成装置から、タスクを遂行できる存在へと進化させます。 - メモリー
永続的なストレージへの読み書き能力。AIエージェントは、メモリーによって会話間の文脈を記憶し、過去のやりとりから学習し、状態を維持します。
簡単な例:ウェブサイト検索
具体的な例で、AIエージェントがどのように機能するかを見てみましょう。
標準的なLLMに「IBM iに関する最新のニュースを見せてください」と依頼すると、問題が発生します。LLMはある時点までのデータでトレーニングされているので、最新の出来事やインターネット上の現在進行形の情報にアクセスできません。そのため、LLMはもっともらしいけれども、誤った情報(いわゆる、ハルシネーション[幻覚]と呼ばれる現象)を作り上げてしまう可能性があります。
では、LLMにウェブサイト検索機能のようなツールを与えたらどうなるでしょうか?同じ質問をした場合、AIエージェントならば以下のようなことが可能になります。
- 最新の情報が必要であることを認識する
- ウェブサイト検索ツールを使用して、最近の記事を探す
- 実際の検索結果を読み取る
- 上述の結果を使用して、正確かつ最新の回答を提供する
質問は同じであっても、結果は異なります。機能拡張が全てを変えたのです。
これが基盤です。機能拡張によって強化されたLLMは、IBM i環境のような実際のシステムと対話できるAIエージェントになります。
AIエージェントとは?
機能拡張によってLLMに能力が追加される仕組みを理解したところで、真の「AIエージェント」を構成する要素を見てみましょう。
AIエージェントは、LLMを基盤とする自律型プログラムであり、テキストを生成するだけでなく、意思決定を行い、目標を達成するためにアクションを起こします。
チャットボットは回答後に停止するのに対して、AIエージェントは一連のステップを実行し、結果を確認し、アプローチを調整して、タスクが完了するまで継続的に作業を実行します。
AIエージェントは、以下のような高度な自動化機能を持つと考えてください。
- 生産管理や販売管理のようなビジネスシステムからデータを読み取り、そのデータ内のパターンを認識することで文脈を理解する
- 事前に定義されたルールと状況とが完全に一致しない場合でも、目標に対して現状を評価し意思決定を行う
- データベースのクエリー、通知の送信、レコードの更新など、複数のシステムとインターフェースにまたがるアクションを人間の継続的な介入なしに実行する
- それぞれのアクションから学んだ内容に基づいてアプローチを調整し、状況に応じて異なるツールを選択する
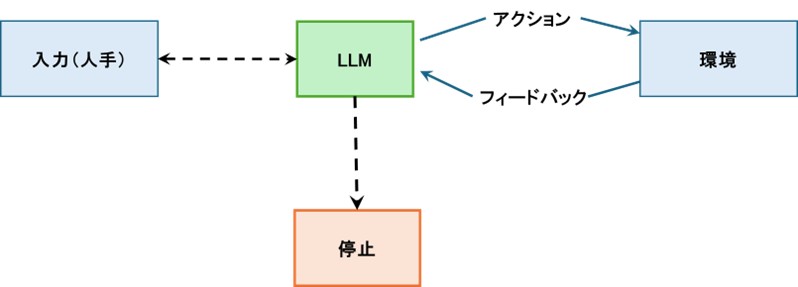
図2.チャットボットは回答を出すと停止。AIエージェントはループ内で環境と相互作用。
コア・コンセプト
AIエージェントについて簡単に考えてみましょう。AIエージェントは目標を達成するためにツールをループして実行します。
仕組み(概念的)
AIエージェントは、簡略化すると以下のよう構造になります。
env = Environment()
tools = Tools(env)
system_prompt = "Goals, constraints, how to act"
task = "Peform task X, Y, Z"
while True:
action = llm.run(task, system_prompt + env.state)
env.state = tools.run(action)
各コンポーネントの詳細は以下のとおりです。
- env:AIエージェントが動作しているシステム(この場合は IBM i オペレーティング・システム)
- tools:AIエージェントに付与する具体的な機能
- system_prompt:AIエージェントの役割と制約を定義する指示
「これがあなた(AIエージェント)であり、あなたのアクションの方法です」 - task:ユーザーのリクエストまたは入力
ロジック
エージェント・ループ内では以下の処理が行われています。
- 人間の入力によって、最初の目標またはタスクが提供される
- LLMはタスクを受け取り、実行するアクションを決定する
- アクションは(IBM iにおけるクエリーのように)環境内で実行される
- 環境から結果とともにフィードバックが返される
- LLMはフィードバックをもとに次のアクションを決定し、ループは継続
- 目標達成時(または、AIエージェントが継続不可能と判断したとき)に停止する
IBM iにとってAIエージェントが重要な理由
環境、ツール、指示というコンポーネントがあれば、IBM i用の強力なAIエージェントを構築できます。
複雑なアーキテクチャーまたは高度なAIの専門知識は不要です。必要なのは以下です。
- 環境:IBM iへの接続
- ツール:エージェント・ツールとしてラップされたSQLサービス(知識とツールの機能拡張)
- 指示:AIエージェントの動作に関する明確なガイドライン(システムプロンプト)
このシンプルさこそが、真の力です。
【続編記事】 IBM i 向けAIエージェントの構築法本記事は、TechChannelの許可を得て「AI Agents for IBM i: A Comprehensive Introduction」(2025年11月13日公開)を翻訳し、日本の読者に必要な情報だけを分かりやすく伝えるために一部を更新しています。最新の技術コンテンツを英語でご覧になりたい方は、techchannel.com をご覧ください。










本記事は、Tech Channelの連載記事「AI With IBM i」の第3弾である「AI Agents for IBM i: A Comprehensive Introduction」を翻訳・転載したものです。
大規模言語モデル(LLM)を知識、ツール、メモリーによって強化し、AIエージェントが実際にアクションを起こせるようにする方法について、IBMのAIスペシャリストであるアダム・シェディヴィ氏とデヴァンシュ・クマール氏が説明します。 (編集部)