

サンプルプログラムはこちらから!
前々回、前回と、生成するEXCELファイルを見やすくする仕組み=DEFファイルの作成について説明してきました。
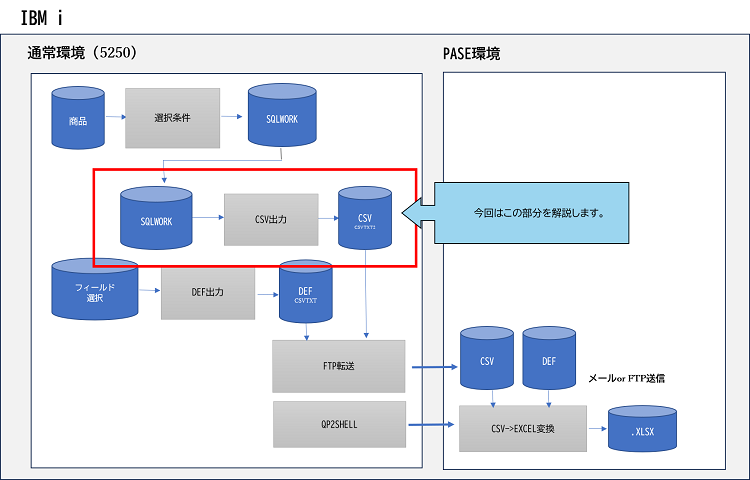
今回は、いよいよデータ本体、すなわちIBM i上にあるマスターファイルからCSVファイル(物理ファイル)に書き出す部分を説明します。
具体的には、
- 5250画面にて入力された選択条件によって作成されたSQL文(QTEMP/SQLWORKに出力:第2回参照)を読込み、SQLを実行。
- IBM i上の商品マスターから選択条件に合致した商品コードを取出し、商品マスターデータを取得します。
- 取得した商品マスターデータはフィールド選択ファイルに従ってCSVデータを出力します。
- フィールド選択ファイルはカラム(フィールド)出力順でCSVデータ(QTEMP/CSVTXT2)を出力します。
- CSVヘッダー(タイトル)はフィールド選択ファイルの情報を使用してCSVの1行目に出力します。
これらを今回の第5回記事で解説します。
ソース・プログラムは当連載第1回でご案内したサンプル・ライブラリーに格納してありますので、全容はそちらでご確認ください。
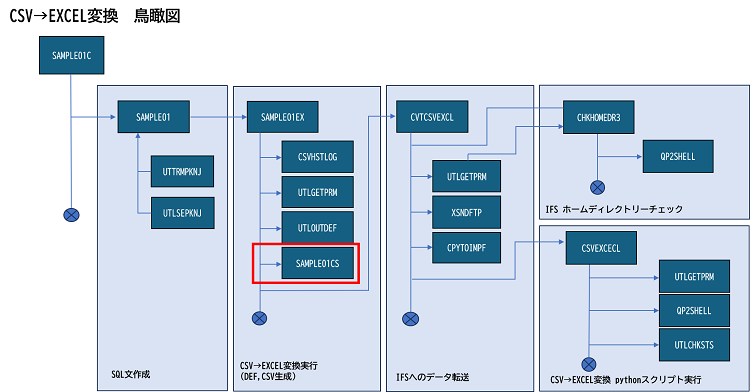
1. CSVファイル作成
第2回記事で解説した、SQLWORKに出力されているSQLを実行しデータを取得します。
データ1件毎にパラメータの&IDでCSVCOLL1(第3回記事参照)に定義されている出力カラムに従ってCSVデータを出力します。
&ROWCNTはSAMPLE01でデータ件数を取得したものがCLにパラメータとして渡されたものです。
本来はSQLDA(SQLデータエリア)を使用すべきですが、時間の関係上実装していません。SQLで取得しているフィールドは主キーとなるフィールドのみです。取得した主キーフィールドでデータをCHAINする仕組みとしています。
① 手順1:CSVファイル作成プログラム内ではCSVCOLL1をパラメータ&IDでプログラム内テーブル(DS)に読込みます。
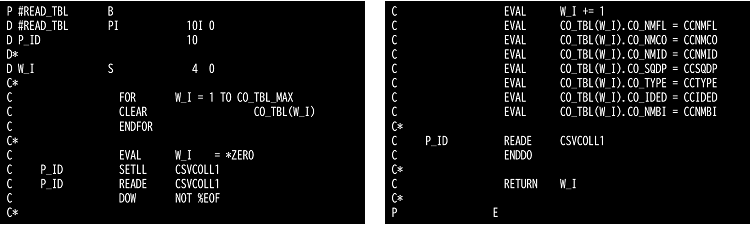
② 手順2:CSVデータ出力
【CSVデータ出力処理】
CSV明細データはSQL FETCHにてデータが無くなるまで処理を繰返します。
標識80はFETCHにて取得するデータが無い時とSQLエラーの時に*ONになります。

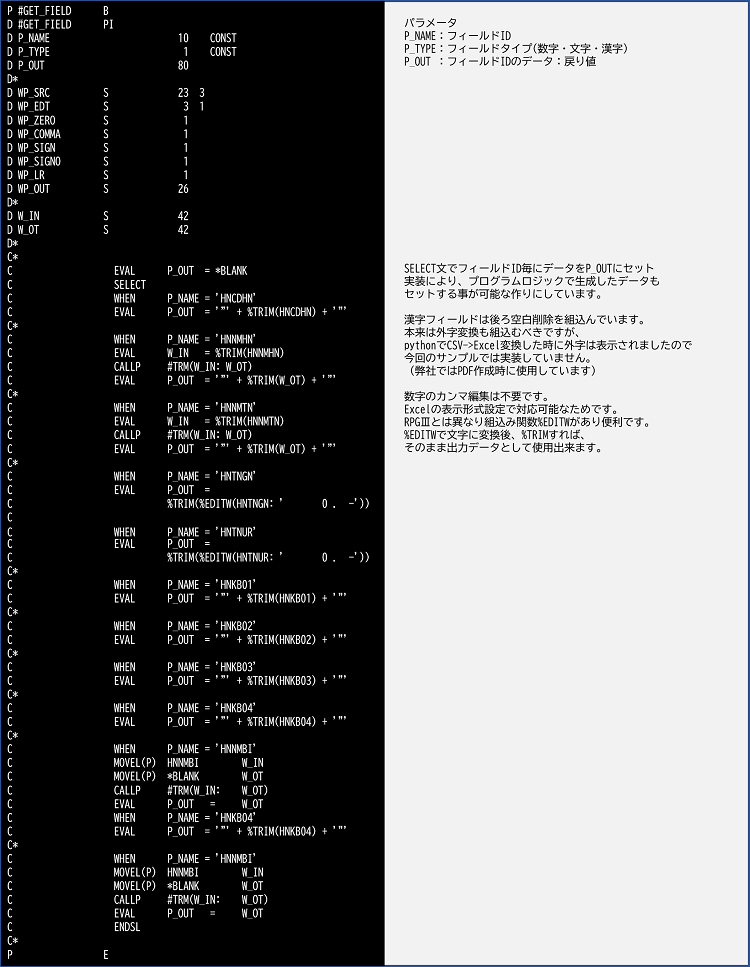
【CSVヘッダーデータ出力処理】

【CSV明細データ出力処理】

【CSVフィールドデータ取得処理】










日本アイ・ビー・エム株式会社が毎月開催しているIBM Powerユーザーのための自由な語り場「IBM Power Salon」(月1回、第二水曜日の朝9時から開催)をご存じでしょうか?
https://www.ibm.com/blogs/systems/jp-ja/ibm-power-salon/
2023年1月11日に開催された第14回の、株式会社 電業様による「惜しみなく共有しちゃいます、根っからのエンジニアが語る、IBM i 内製化のリアル。」では、既存IBM i環境を見事に活用し、自作でIBM i と自動倉庫をつなげDXを実現された素晴らしい事例が披露されました。
https://video.ibm.com/recorded/132452956
とはいえ、1時間の講演時間では語りきれなかった詳細は、きっと他のIBM i ユーザーの方にも参考になるはず!ということで、株式会社電業 総務部 竹本伸明様に“内製DX”について具体的にご説明いただきます。読めばきっと、「IBM i でここまでできるんだ!」と目から鱗が落ちるはずです!