
サンプルプログラムはこちらから!
3回目では、生成するEXCELファイルを見やすくする仕組みを説明します。
PCOMMやACSでもEXCELにデータ変換可能ですが下記の理由により変換されたデータは見易くありません。
弊社ではテータ変換後にEXCELで表示形式を設定・列幅設定・列並び変更・1行毎に色分けするためにテーブル設定するなどを行っていました。
(コラム)
前述した通り、通常データ以外にEXCELの表示編集情報を持つのがDEFファイルです。
上記の2つの情報からDEFファイルを生成します。
このファイルはEXCELの表示形式を設定するのに使用する共通情報です。
① CSVEDTのDDSソース (主要なフィールドのみ記載)
② CSVEDTの登録データ
上記の登録データは弊社で使用しているものです。企業により使用する編集方法は異なると思います。
このファイルはCSVファイルのカラムヘッダー及びカラムの出力順序とEXCELの表示編集方法を持ちます。
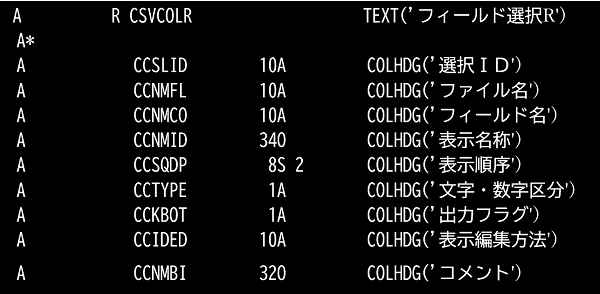
①CSVCOL物理ファイルのDDSソース
②CSVCOLL1 論理ファイルのDDSソース
論理ファイルのキーは選択IDの次に表示順序をキーとしています(並び替え)。これにより表示順序で出力するフィールドが取得できます。
※サンプルプログラムでセットされているデータは下記画面になります。
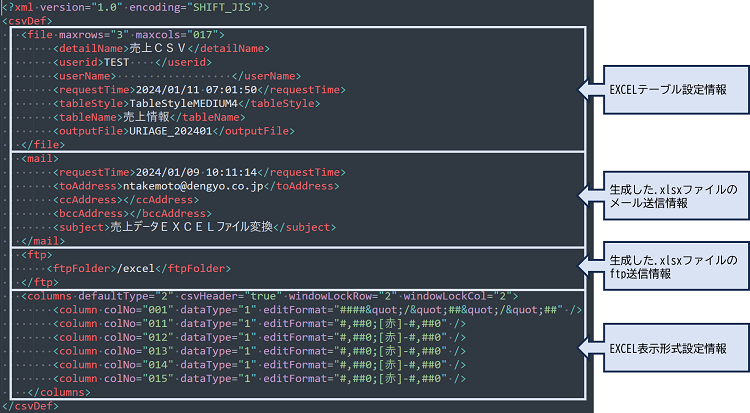
下記が生成されたサンプルのDEFファイルです。(※ピボット集計・グラフ描画の記述を除いたもの)
設定時は、xmlのcolNo属性で指定されるEXCELのカラム位置で表示形式を設定します。
DEFファイルはXML形式です。当然XMLで使用する文字がデータに含まれる場合は文字の置換処理が必要です。
【変換テーブル】
【UTLXMLESCを呼び出す処理】
CSVファイルを使用する時、文字列であればダブルクォート(“”)で囲みます。サンプルプログラムSAMPLE01CSも行っています。今回のサンプルではデータにダブルクォートが存在する事を想定していません。本来文字列をダブルクォートで囲む時に、データにあるダブルクォート文字のエスケープ処理が必要です。(※このエスケープ処理方法はソフトによって異なるケースがありますので注意して下さい。)
【変換前】AAA”BB”
【変換後】AAA””BB””
【使用方法】
【使用するソース】
英小文字の5026>-<5035間のコード変換問題を避けるため、パラメータ関連はファイルに保存する事にしています。
▼サンプルプログラムでセットしているパラメータ
上記のようにID毎に最大5個まで(もっと増やしてもよかったかも知れません)設定できます。IDは英小文字問題を避ける為全て大文字です。パラメータ取得プログラム(UTLGETPRM)を作成しCLで使えるようにしました。このプログラムは5026<->5035のコード変換プログラム(UTLCVTEBC)を必要時にCALLしています。
CALL UTLGETPRMがパラメータ取得のプログラムです。2番目のパラメータは5026<->5035のコード変換指定です。※ *NOは変換しない。
(参考:EXCEL用パラメータファイルの一部)
DEFファイル・CSVファイル・BNDファイルはCRTPFコマンドで事前にライブラリーリストにあるライブラリーに作成します。
DEFファイルDDSソース
DEFファイル(XMLファイル)を格納する為の物理ファイルです。
CSVファイルのDDSソース
BNDファイルのDDSソース
SQL作成プログラムから、下記ILECLPプログラムが起動されます。
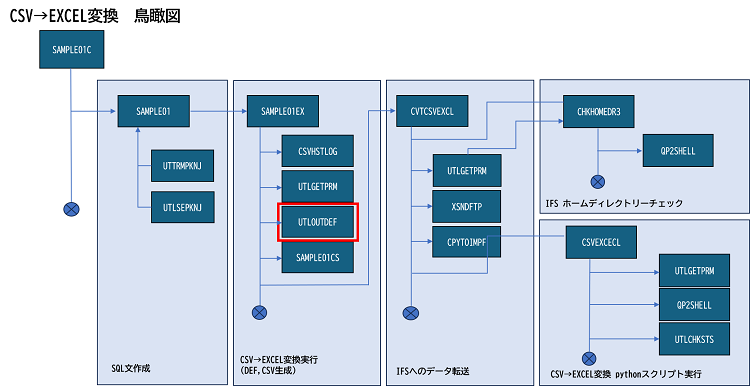
ソース・プログラムは当連載第1回でご案内したサンプル・ライブラリーに格納してありますので、全容はそちらでご確認ください。
(弊社では、9桁の数字は頭3桁―後ろ6桁と表示しています)
これらをデータ要求される度に行うのはベターではない(面倒)と思い自動化できないかと考えました。
上記のEXCELに設定する表示編集情報を別ファイル出力する事にしました。このファイルがDEFファイルです。
DEFファイルはXML形式ファイルです。XMLファイルを採用した理由は、データを抽出するのは面倒ですが拡張性に優れ可読性が高いためです。
またXML整形ツールやDTDを作成する事でデータの検証が行える点もあります。サンプルではDTDを作成していません。
今回XMLを採用した理由は、CSVはセパレータ文字や制御文字のエスケープ処理はローカル・ルールが多く明確に規定されていないからです。
また最近ではJSONフォーマットを好まれる人もいますが、JSONは可読性が低く構文に誤りがあった時に見つけにくい問題があります。
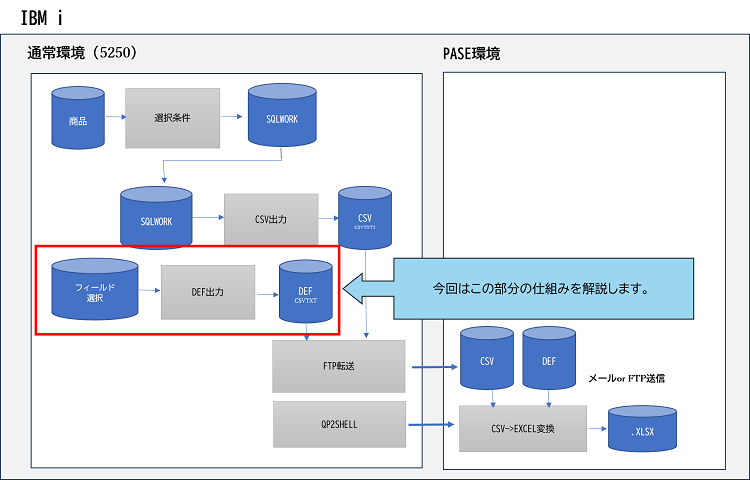
1. セル表示形式設定の仕組み
表示編集情報は(異なるデータをEXCEL化する時)再利用するものが多く、共通利用可能な形で情報を持つ必要があります。
また通常データ出力のヘッダー情報や出力するカラム情報(出力順序)も持つ必要があります。これらは2つのファイル情報で実現します。
尚サンプルで用意しているファイルのデータ保守プログラムは用意していません。UPDDTAコマンド(DFU)でデータ保守して下さい。
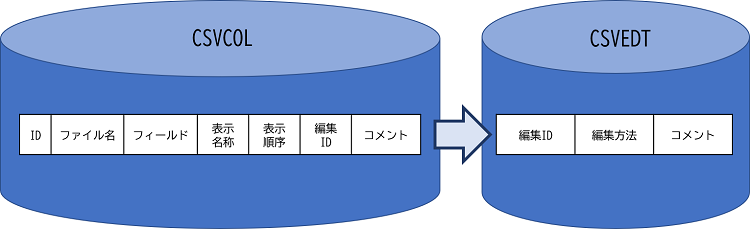
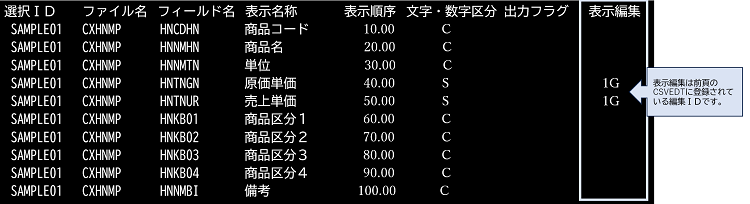
1.1. 表示編集情報(CSVEDT)


登録データ画面の編集方法はEXCELにセットする情報です。(セルの書式設定→表示形式→ユーザー定義にセットする情報)
1.2. フィールド選択ファイル(CSVCOL, CSVCOLL1)
選択IDは出力するデータの種類で設定します。

ユーザー毎に異なるフィールドや異なるフィールドの並びを設定したい場合はこのファイルを拡張する事で実装できます。
※上記の内容は企業によって内容が異なるかと思いますのでサンプルでは実装していません。
1.3. 生成されたDEFファイル
このファイルをpythonスクリプトで読込み.xlsxファイルにOpenpyxlライブラリーで設定します。
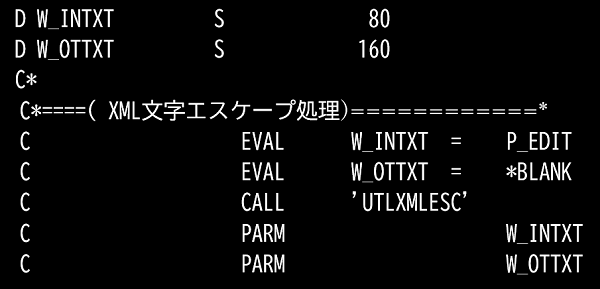
2. XML文字エスケープ処理(UTLXMLESC)
このプログラムはRPGⅢからCVTRPGSRCコマンドでILERPGに変換したものです。
本来テーブルを使用せずDSで定義するほうが分かり易くなりますが、時間の関係でリメイクはしていません。

XML文字エスケープはILERPGからは左記の様にCALLで呼び出します。
W_INTXTに変換する文字列をセット
W_OTTXTに変換された文字が返されます。
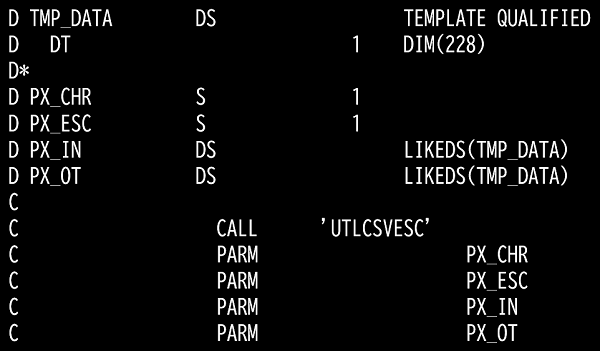
3. 3 CSV文字エスケープ処理(UTLCSVESC)
データ中にダブルクォート文字が存在した場合は、ダブルクォート文字の前にエスケープ文字を挿入するソフトを作成しています。
この処理はpythonで使用しているCSVファイルを読込むpandasライブラリーでダブルクォート文字をエスケープする文字に合わせています。
エスケープする文字はパラメータで渡していますので、変更する場合はパラメータに渡す値を変更して下さい。漢字文字(X’0E’とX’0F’に囲まれた文字列)は変換しません。必要に応じてCLやILERPGで使用して下さい。変換後の最大文字列長は228バイトです。CLで使用する場合はコマンドを作成しています。
No.
パラメータ
入力/出力
補足
1
PX_CHR
入力
ブランクの時、ダブルクォート文字に設定される
2
PX_ESC
入力
ブランクの時、ダブルクォート文字に設定される
3
PX_IN
入力
変換する文字列 最大228文字
4
PX_OT
出力
変換した文字列 最大228文字
4. パラメータ取得処理
4.1. パラメータ取得
(EXCEL以外:UTLGETPRM、EXCEL用:UTLGETEXCL)
この手法であれば、DBには必ずCCSIDがセットされ、適切に実行しているジョブのCCSIDに変換されるからです。SEUで5026か5035のどちらで編集したか、また誤ったCCSIDで編集する事はありません。このファイル必要時にIDを指定して取得します。IDはCCSIDの問題を回避する為、全て英大文字でセットします。DEBUGする際に一時的に値を変更しテストするのも便利でした。(ソースを修正するとケアレミ・ミスの可能性が発生します。)また下記特殊文字列を用意しています。特殊文字列を設定すると内容値に変更されます。
No.
特殊文字列
セットされる値
備考
1
%USER%
IBM iにサインインしたユーザーID
英大文字 最大10文字
2
%PGM%
実行しているプログラムID
英大文字 最大10文字
3
%WSID%
ワークステーションID(ジョブ名)
英大文字 最大10文字
4
%DATE%
実行日付8桁
編集表示はしません
5
%TIME%
実行時間6桁
編集表示はしません

4.1.1. CLでパラメータ取得 変数定義

4.1.2. パラメータ取得処理
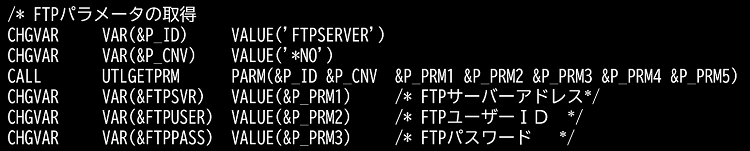
取得したP_PRM1~P_PRM5の5つのパラメータを実際の変数にセットします。
上記の画面はFTP関連情報を取得しています。本来はコマンド化すべきですが、時間の関係で実装には至りませんでした。
※RTVxxxxコマンドのようなものを作成すればもっと便利だったと思います。
またパラメータ取得はEXCEL用があります。情報の持つ意味合いとユーザー変更可能パラメータとしたかった為、あえて分けています。
5. 準備作業
BNDファイルに関して今回は説明しません。(※複数のCSVを纏めて1つのEXCELにする定義ファイルです。)
QTEMPに作成します。
単純にレコードが長いファイルになります。
CRTPFで作成すると弊社の環境ではCCSID=5026で作成されます。
「CRTPF FILE(EXCELLIB/CSVTXT) SRCFILE(EXCELLIB/QDDSSRC)」

QTEMPに作成します。
単純にレコードがより長いファイルになります。
CRTPFで作成すると弊社の環境ではCCSID=5026で作成されます。
「CRTPF FILE(EXCELLIB/CSVTXT2) SRCFILE(EXCELLIB/QDDSSRC)」

QTEMPに作成します。
単純にレコードが長いファイルになります。
CRTPFで作成すると弊社の環境ではCCSID=5026で作成されます。
「CRTPF FILE(EXCELLIB/CSVTXT3) SRCFILE(EXCELLIB/QDDSSRC)」

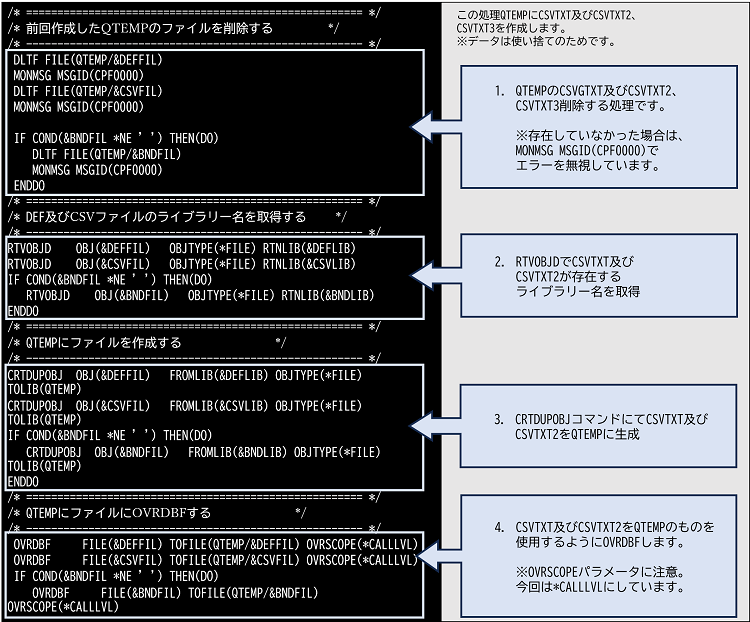

CSVファイル(CSVファイル)を格納する為の物理ファイルです。
BNDファイル(XMLファイル)を格納する為の物理ファイルです。
いいねと思ったらシェア










日本アイ・ビー・エム株式会社が毎月開催しているIBM Powerユーザーのための自由な語り場「IBM Power Salon」(月1回、第二水曜日の朝9時から開催)をご存じでしょうか?
https://www.ibm.com/blogs/systems/jp-ja/ibm-power-salon/
2023年1月11日に開催された第14回の、株式会社 電業様による「惜しみなく共有しちゃいます、根っからのエンジニアが語る、IBM i 内製化のリアル。」では、既存IBM i環境を見事に活用し、自作でIBM i と自動倉庫をつなげDXを実現された素晴らしい事例が披露されました。
https://video.ibm.com/recorded/132452956
とはいえ、1時間の講演時間では語りきれなかった詳細は、きっと他のIBM i ユーザーの方にも参考になるはず!ということで、株式会社電業 総務部 竹本伸明様に“内製DX”について具体的にご説明いただきます。読めばきっと、「IBM i でここまでできるんだ!」と目から鱗が落ちるはずです!