

サンプルプログラムはこちらから!
第1回目でIBMiのデータをEXCEL出力するサンプルを紹介させて頂きました。今回からは、その詳細を何回かに分けて説明します。
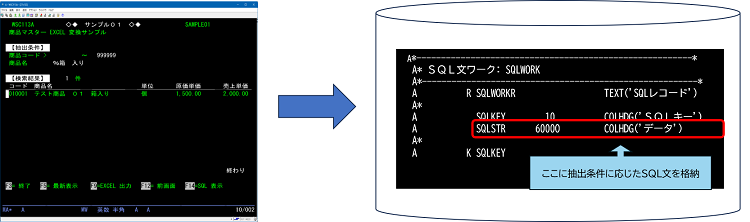
今回は上記題名にもあるように5250画面で抽出条件を入力し、入力された条件からSQL文を生成しテーブル(物理ファイル)に書込むまでになります。
また、RPGLEプログラムでも参考になる部分もありますので併せて説明します。
ソース・プログラムは当連載第1回でご案内したサンプル・ライブラリーに格納してありますので、全容はそちらでご確認ください。
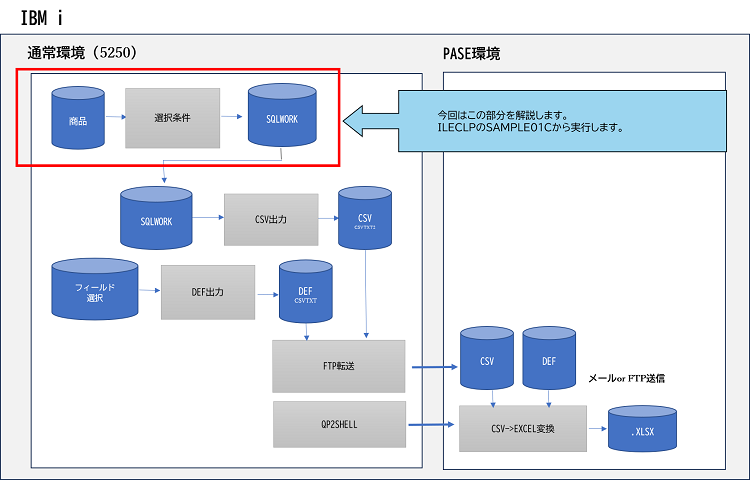
SQLWORKは、CRTPFでライブラリーリスト上のライブラリーに作成します。
SQLWORKは条件入力により生成されるSQLが毎回異なり、実行するJOB毎に排他する必要があります。サンプルプログラムでは、出力条件入力画面を呼び出すCLPで、CRTPFにて生成されたテーブルをCRTDPUOBJコマンドでQTEMPに生成し、OVRDBFコマンドでSQLWORKはQTEMPのものを使用するようにします。
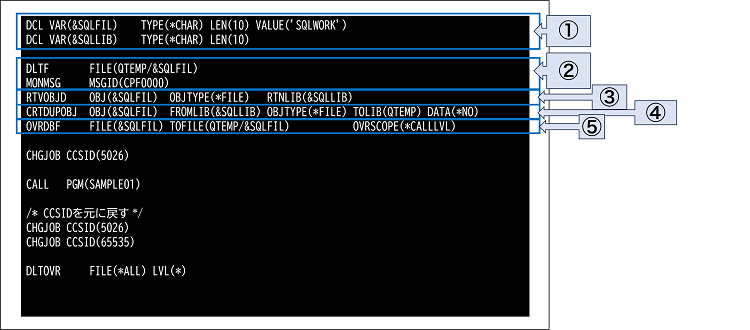
サンプルプログラムを表示するCLプログラムの流れは下記になります。
- 最初にCL変数を定義し、生成したSQKWORKの名称で初期化します。またSQLWORKの存在するライブラリー名を保管するSQLLIBも定義します。
- 一時的にQTEMPでSQLWORKを使用しますが、前回使用したものが残っている事がありますので、DLTFコマンドでQTEMPのSQLWORKを削除します。
※DLTFコマンド実行時にQTEMP/SQLWORKが存在しない時にエラーとならない様にMONMSG MSGID)CPF0000)でエラーを無視する様にします。 - RTVOBJDコマンドで、SQLWORKの存在するライブラリーをCL変数に取得します。(※既定値では*LIBLから探してくれます。)
- CRTDUPOBJコマンドで既存ライブラリーからQTEMPへテーブルを複製します。(パラメータ DATA(*NO)にしているため、データは複製されません。)
- OVRDBFコマンドでSQLWORKを既存ライブラリーにあるものではなく、QTEMPのものを使用するようにします。
(※ILE版CLPでは、OVRDBFコマンドの適用範囲のデフォルトが*ACTGRPDFNとなりますので、OVRSCOPEパラメータで*CALLLVLに変更する事で活動グループに関係なくCALLで呼ばれた範囲で有効となります。)
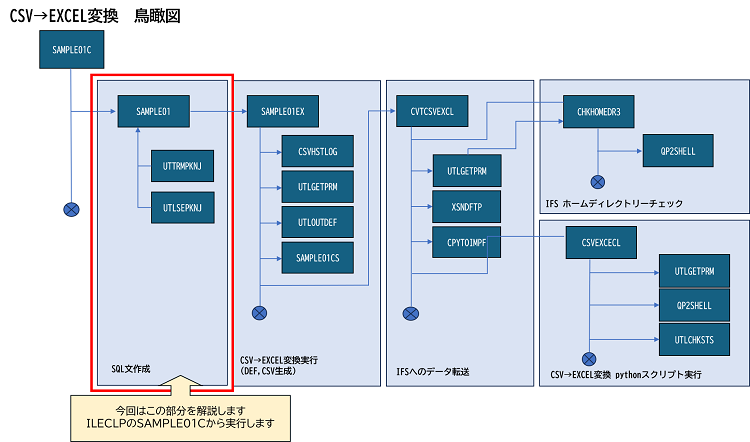
次に前述したILECLPから起動されるSAMPLE01(SQL文作成)を説明します。
サンプルプログラムでは、5250画面で入力された抽出条件からSQL文を作成しています。
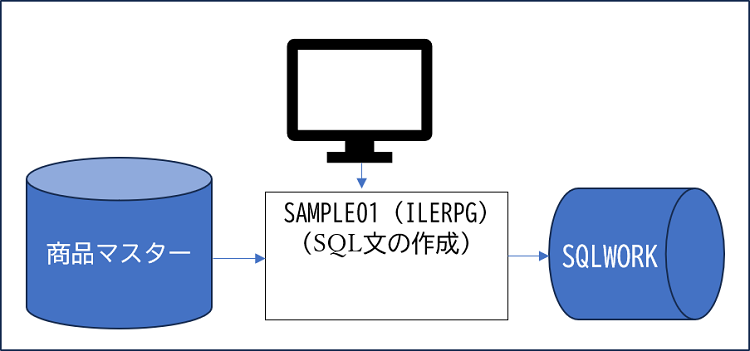
作成されるSQL文はテーブル(物理ファイル):SQLWORKに出力します。条件入力時はデータ件数が必要ですが、データ出力ではSQLを実行し、SELECTで指定されたカラムのデータが必要です。この為、2種類のSQL文が必要です。
データ件数を出力するSQLをテーブルに出力する必要はありませんが、生成したSQL文を確認する為に出力しています。
(※サンプルプログラムでは、F14を押下する事で画面に表示する様にしていますが、SQL文が長くなると1画面に表示できなくなり、サブファイルで実装するのは面倒だったためです。)
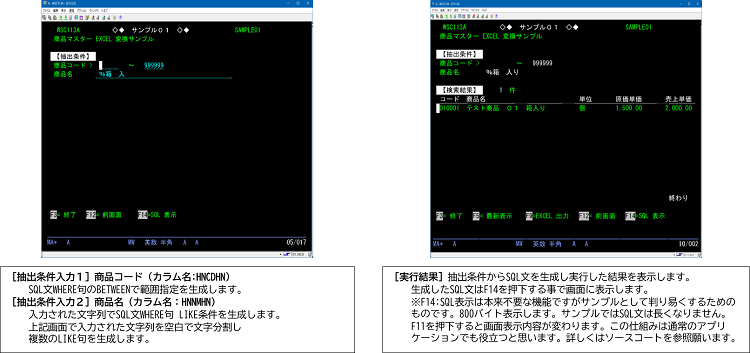
抽出条件入力画面
ヘッダーの抽出条件(商品コード範囲及び商品名の文字列検索)を入力し実行キーを押下すると、SQL文を作成し実行結果を表示します。
生成したSQL文はQTEMP/SQLWORKに出力されます。
生成されたSQL文
- 商品コード条件
下記画面SQL文の HNCDHN BETWEEN ‘ ‘ AND ‘999999’ になります。 - 商品名条件
下記画面SQL文の AND (HNNMHN LIKE ‘%箱%’) AND (HNNMHN LIKE ‘%入%’) になります。
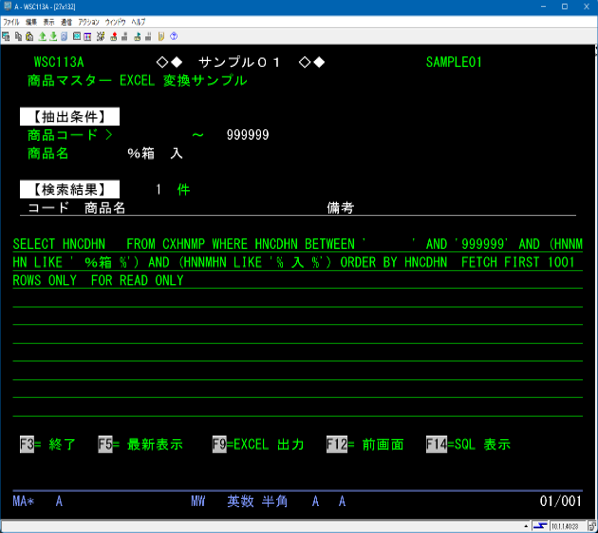
これは前述した通り、漢字空白で文字列を分割しています。またLIKE句の%は全角もしくは半角でも問題なく機能します。
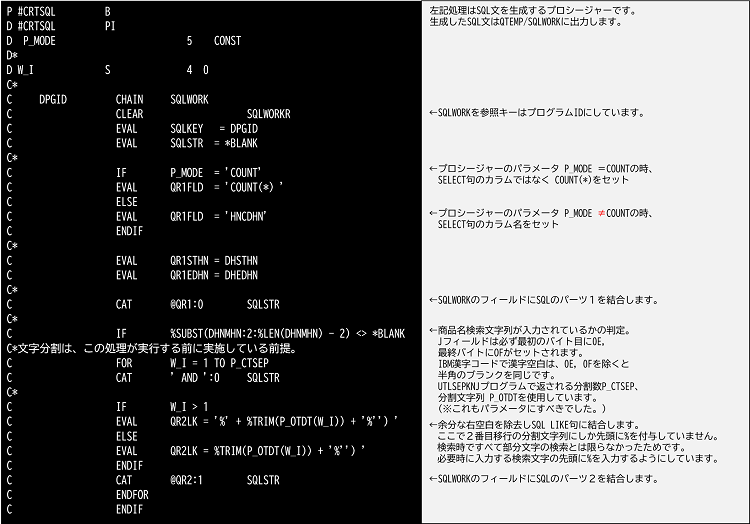
SQL文の生成
では、どうやってILERPGでSQL文を生成しているかを説明します。単純な話ですが、SQL文と言っても単なる文字列です。
サンプルでは、D仕様書にDSで定義し可変となる箇所には画面上で入力した値をセットします。
漢字空白分割は別プログラム(UTLSEPKNJ)にしており、最大5分割・分割文字数最大42バイトまで行います。※テストプログラム TSTSEPKNJで動作確認できます。最大文字数はソースコードを少し修正するだけで長くする事が出来ます。0E及び0Fの存在しないデータは処理しません。
① パーツ1
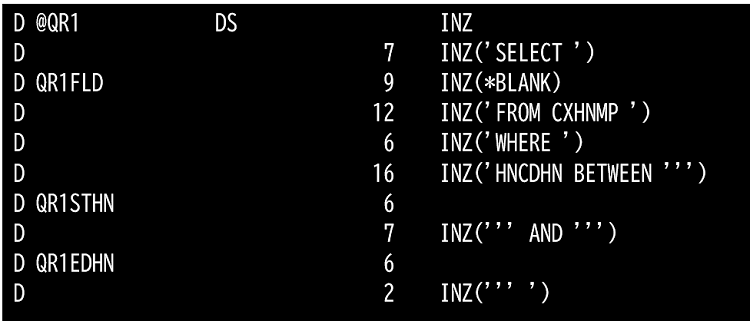
QR1FLDは商品コード(HNCDHN)もしくは、COUNT(*)をセットする想定の長さにしています。もっと長くなる場合は左記のDSを複数に分けます。
(例)
パーツ1A SELECT
パーツ1B FROM CXHNMP
パーツ1C WHERE HNCDHN BETWEEN …
パーツ1A~パーツ1CをEVALもしくはCATで文字結合します。
サンプルプログラムではCATで文字結合しています。
② パーツ2

QR2LKは商品名の文字列検索(漢字分割で生成された分離文字で複数のLIKE句を、今回はAND条件で生成します。)
③ パーツ3
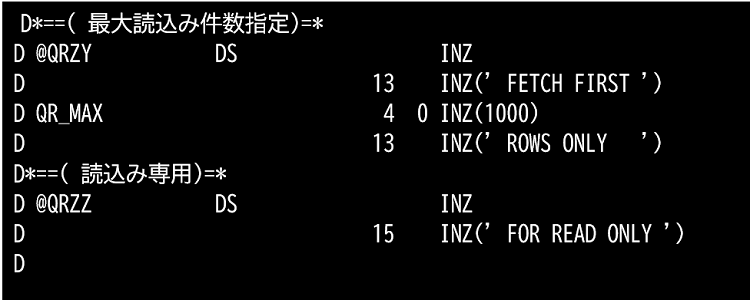
SQLで上限検索件数を更新不可とするSQL句になります。
QR_MAXは最大読込み件数+1にセットします。+1は最大件数を超えたかを判定する為の件数です。データ読込みは最大読込み件数までです。
※大量のレコードを読込むと処理時間がかかります。また大量のデータが必要かの疑問もありますので一定件数を超えた時は警告を表示し続行するか操作者に確認を促した方が良いでしょう。
FOR READ ONLYはデータを変更できないモードでデータ読込みをSQLに明示します。
(※レコードロック回避)
パーツを組立ててSQLを生成

追加情報
1. 漢字後ろ空白削除(UTLTRMKNJ)
漢字フィールドの後ろ全角ブランクを削除するプログラムです。DEFやCSV作成に余分な空白を出力しないようにするものです。
下記はテストプログラム(TSTTRMKNJ)からUTLTRMKNJをCALLしています。X’0F’の位置が変わっている事が確認できます。

ILERPGの%TRIM組込み関数はX’0E’と’X’0F’に囲まれた漢字フィールド内には対応していません。(テストしました。)
上記画面のようにJフィールド(漢字のみ)の時に全角ブランクを削除します。%TRIMを組み合わせて使用します。
2. 2つの漢字フィールド結合(UTLCATKNJ)
この2つの漢字フィールド結合は、後ろ空白削除後(UTLTRMKNJ)、フィールドを結合します。結合モード=Yにする事で結合した2つのフィールド間に1個のブランクを挿入します。下記はテストプログラム(TSTCATKNJ)からUTLCATKNJをCALLしています。
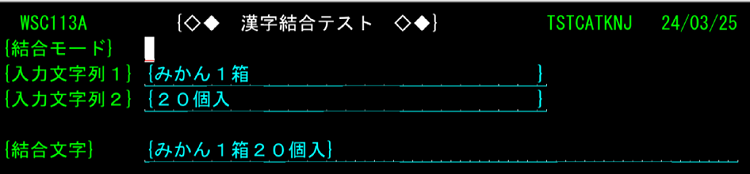
① 結合(結合した2つのフィールド間にブランクなし:結合モード=ブランク)
② 結合(結合した2つのフィールド間も1個のブランク:結合モード=Y)
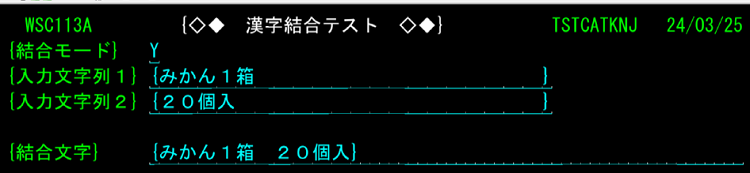
尚、UTLCATKNJはサンプルプログラムでは使用していません。このプログラムは住所1と住所2等を連結し、1つのフィールドとするためのものです。
今回は紹介していませんが、運送会社のレーザープリンタ対応する時に使用しています。
(※一部の運送会社は住所が1つのフィールドとなっています。)
3. 漢字分割(UTLSEPKNJ)
漢字分割はIBMiでWEB検索する際に、複数ワードで検索できるようにするためのものです。
弊社でも使用しているモジュールをサンプル用にILERPGでリメイクしたものです。漢字文字を最大5つまで全角ブランクで分割します。
商品名や備考等、漢字フィールドで検索する際、SQLのLIKEで文字列検索するためのものです。
下記はテストプログラム(TSTSEPKNJ)からUTLSEPKNJをCALLしています。
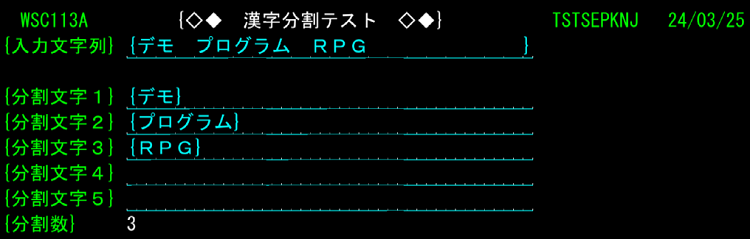
上記画面のように入力した文字列を分割し、分割数もパラメータとして返します。分割数でFOR文をループしSQLのLIKE句を生成する事が可能です。










日本アイ・ビー・エム株式会社が毎月開催しているIBM Powerユーザーのための自由な語り場「IBM Power Salon」(月1回、第二水曜日の朝9時から開催)をご存じでしょうか?
2023年1月11日に開催された第14回の、株式会社 電業様による「惜しみなく共有しちゃいます、根っからのエンジニアが語る、IBM i 内製化のリアル。」では、既存IBM i環境を見事に活用し、自作でIBM i と自動倉庫をつなげDXを実現された素晴らしい事例が披露されました。
https://video.ibm.com/recorded/132452956
とはいえ、1時間の講演時間では語りきれなかった詳細は、きっと他のIBM i ユーザーの方にも参考になるはず!ということで、株式会社 電業 総務部 竹本伸明様に“内製DX”について具体的にご説明いただきます。読めばきっと、「IBM i でここまでできるんだ!」と目から鱗が落ちるはずです!