

[自習環境の登録申込の受付最終日:2026年2月26日(木曜日)]
詳細はこちら
前回の復習
「第六回 データベース – ネイティブ・アクセス(照会プログラム)」では、RPG でデータベースを操作するためのネイティブ・アクセスの基本について解説しました。ネイティブ・アクセスは、プログラム内で使用するファイルとその使用方法を定義し、レコード単位で情報にアクセスする命令を使用します。
この方法を使用する基本的な3つのプログラムを通して、ファイルに対するレコードのランダム検索および順次読み取りについては理解できたと思います。
またデータベース・ファイルには2種類のアクセス・パスがあることも説明しました。
今回は、前回の内容を前提として、ポインター操作、レコードの更新と削除および追加をネイティブ・アクセスで行う方法について解説します。
今回の内容をしっかり理解することにより、新たなプログラムの作成のみならず、現役で使用されている RPG プログラムの理解もぐっと深まるはずです。
それではポインターの操作から始めましょう。
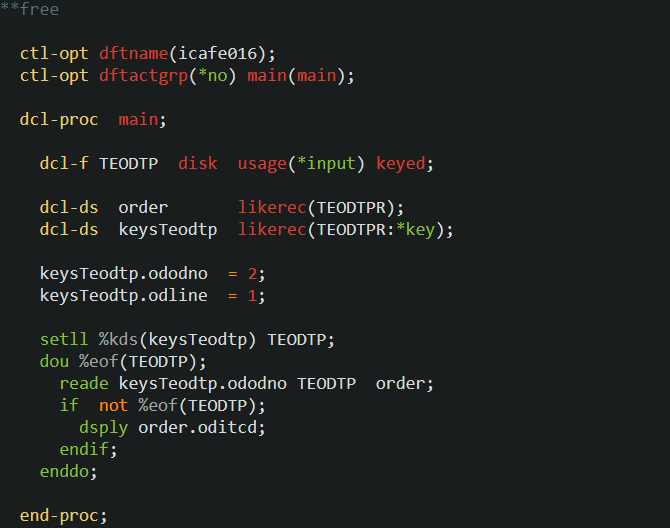
icafe016 プログラム(ポインターの操作)
ネイティブ・アクセスにおいては2種類のアクセス・パスのどちらを使用するかを DCL-F で指定し、ポインターを基準にレコードにアクセスします。主に使用されるアクセス・パスは、キー順アクセス・パスだと思います。
ポインターは、ファイルがオープンされると、アクセス・パスの先頭に位置づけられ、ファイルがクローズされるまでその位置をシステムが記憶します。
RPG にはポインターの位置を操作する命令が用意されており、レコード単位の処理を行う命令と合わせて、最短のI/Oで必要なレコードのみをアクセスすることが可能になっています。
ポインターを操作する命令は以下の2種類です。
- SETLL
- SETGT
プログラム内で、現在のポインターの位置に関係なく、読みたいレコードにポインターをセットして参照し直したい場合に便利です。
SETGT(SET Greater Than)は SETLL と逆で、指定された値より大きいキー(もしくは相対レコード番号)を持つ次のレコードにポインターを位置づけます。
今回は受注明細テーブル(TEODTP)を使用して、SETLL と SETGT のポインターのセットの違いについて学習します。
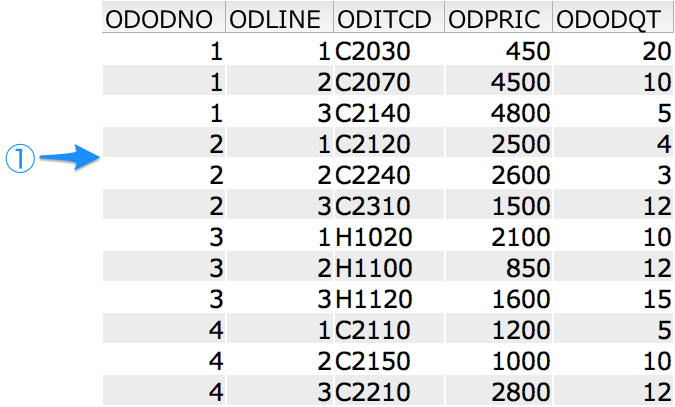
このテーブルには以下のデータが登録されています。
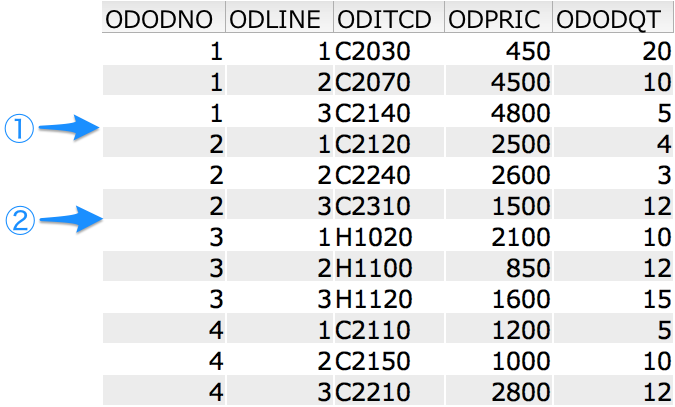 このテーブルのレコードは5つのカラムで構成されます。
このテーブルのレコードは5つのカラムで構成されます。
- ODODNO(5P0)- 受注番号
- ODLINE(3P0)- 行番号
- ODITCD(5A)- 品目番号
- ODPRIC(5P0)- 売単価
- ODODQT(5P0)- 受注数量
P はパック10進数で、直後の 0 は小数点以下の桁数を表します。
このテーブルは、ODODNO昇順 / ODLINE 昇順で定義されたキーを持ち、上記表の並び通りに処理することができると仮定してください。
では SETLL の使用方法についてみていきましょう。
テーブルの第一キーである ODODNO が2のデータを最初に参照できる位置(①)にポインターをセットするには以下のように記述します。
 まず、最初の DCL-DS に注目してください。
まず、最初の DCL-DS に注目してください。前回同様 LIKEREC キーワードを使用して、DCL-F ステートメントで定義したファイルのレコード様式名をもとにデータ構造を定義しますが、今回は LIKEREC キーワードの2番目のパラメータに *KEY を指定しています。
前回は EXTNAME キーワードのところで解説しましたが、LIKREC キーワードにも *KEY は指定可能です。
*KEY により、レコード様式 TEODTPR に定義された ODODNO と ODLINE の2つのキー・フィールドだけを含むデータ構造が定義できます。
今回は keysTeodtp という名前のデータ構造を定義していますが、このデータ構造の使用方法については後ほど解説します。
次に、データ構造の最初のサブ・フィールド keysTeodtp.ododno に ’2’ をセットし、SETLL ステートメントを実行しています。
 SETLL と SETGT の構文は同じで、最初に検索引数を指定し、その後でポインターをセットするファイル名を指定します(ファイル名はレコード様式名でも構いません)。
SETLL と SETGT の構文は同じで、最初に検索引数を指定し、その後でポインターをセットするファイル名を指定します(ファイル名はレコード様式名でも構いません)。
最初のサンプルでは、受注番号2で SETLL を実行しているので、ポインターは①の位置にセットされます。
では以下を実行すると何が DSPLY で表示されるでしょうか?
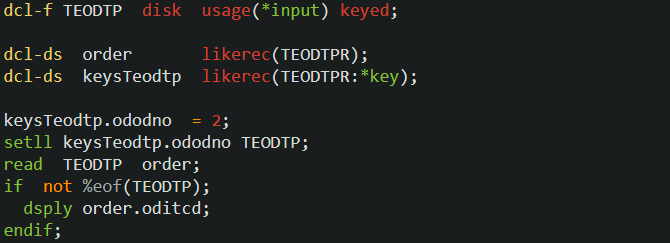 READ は「ポインターの次のレコードを読む」でしたよね。
READ は「ポインターの次のレコードを読む」でしたよね。実際に読まれるレコードは、ODODNO=2、ODLINE=1、ODITCD=C2120 なので、DSPLY で表示されるのは ‘C2120’ です。
では上記のコードに続けて以下を実行してみましょう。
 SETGT は、指定された値より大きいキーを持つ最初のレコードにポインターを位置づけます。
SETGT は、指定された値より大きいキーを持つ最初のレコードにポインターを位置づけます。今回指定したのは ‘2’ なので、ポインターは②の位置にセットされます。
その後の READ で読まれる「次の」レコードは ODODNO=3、ODLINE=1、ODITCD=H1020 なので、DSPLY で表示されるのは ‘H1020’ ですね。
SETLL / SETGT の検索引数には以下を指定することができます。
- *LOVAL(一番小さいキーを持つレコード)
- *HIVAL(一番大きいキーを持つレコード)
*HIVAL は、例えば対象キーがパック10進数の場合は X’99…9F’ など、そのタイプの最大値を表します。
そのため、SETLL でも SETGT でもポインターが位置づけられるのはアクセス・パス内の最後のレコードの直後にセットされることになり、直後の READ は失敗(次のレコードがない)する場合がほとんどなので注意してください。
*HIVAL は SETGT と一緒に使用することで、キーの逆順にレコードを処理したい場合に使用します。
キーの逆順に「次のレコード」を読むには READP を使用します。
キー順に最初のレコードから順次処理するためには「SETLL *LOVAL + READ」、キーの逆順にレコードを順次処理するには「SETGT *HIVAL + READP」と覚えておきましょう。
SETLL と一緒によく使われるのが READE(READ Equal key)命令です。
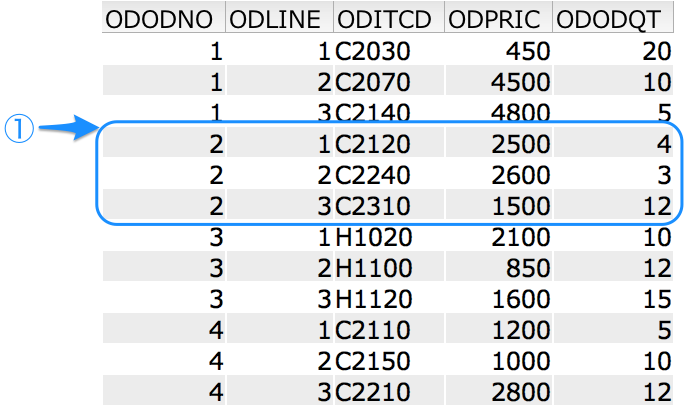 この図のように ODODNO が2のレコード(3レコードのみ)を読み取る場合は以下のように記述します。
この図のように ODODNO が2のレコード(3レコードのみ)を読み取る場合は以下のように記述します。
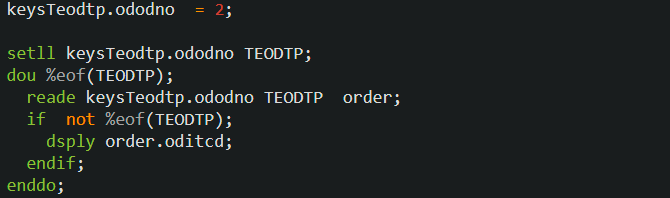 まず、ODODNO に2をセットし、SETLL でポインターを①に位置づけます。
まず、ODODNO に2をセットし、SETLL でポインターを①に位置づけます。次にそのキーを使用して READE しているので、ODODNO が2のレコードを繰り返し処理で3件読んだ後、4回目の READE を実行すると次のレコードは ODODNO が3のレコードになり、検索引数と等しくないので(レコードが存在しても)%EOF 関数は false を返します。
SETLL と READE を使用することで、必要なレコードのみ参照することができますね。
ポインターの操作について、更に深く見ていきましょう。
ポインターを次の①の位置に位置づけるにはどうすれば良いでしょうか?
 このテーブルは ODLINE もキーなので、ODODNO=2、ODLINE=2 で SETLL すれば良さそうです。
このテーブルは ODLINE もキーなので、ODODNO=2、ODLINE=2 で SETLL すれば良さそうです。この2つのフィールドを含むデータ構造 keysTeodtp を定義したのでこれを使って SETLL します。
ただし、このデータ構造名を直接指定するとコンパイル・エラーになってしまいます。
これはこのデータ構造を複数のキー・フィールドの集まり(これを複合キーといいます)と認識しないため、ファイルの第一キーとの属性が合っていないと判断されるためです。
データ構造を複合キーとして処理するためには %KDS 組込み関数と一緒に使用します。
 %KDS は SETLL の他に、SETGT / READ / READP / CHAIN などの命令の検索引数で使用することも可能です。
%KDS は SETLL の他に、SETGT / READ / READP / CHAIN などの命令の検索引数で使用することも可能です。
では、TEODTP テーブルの受注番号(ODODNO)2のレコードのみキー順に読んで、品目番号(ODITCD)を dsply するプログラムを作成してみましょう。
 上記サンプルの READE は以下のように記述することも可能です。
上記サンプルの READE は以下のように記述することも可能です。
1を指定すると、複合キーのうち第一キーのみを使用すると指定することになり、結果的に keysTeodtp.ODODNO の値だけで READE するのと同じ意味になります。
では icafe016.rpgle のソースを登録して、プログラムを作成および実行してみましょう。
対象レコードの品目番号が3つ(C2120, C2240, C2310)表示されれば成功です。
レコードの更新と削除
それでは、ネイティブ・アクセスにおけるレコードの更新と削除について解説していきます。まず SQL での更新と削除を思い出してください。
UPDATE では、更新するフィールドの値も同時に指定できるので、直感的にわかりやすかったと思います。
SQL の場合は処理の対象となるレコードは WHERE の条件により異なります。
1レコードに限定される場合もあれば、複数レコードが対象となる場合もあります。
便利である反面、気をつけなければならない点でもあります。
では、ネイティブ・アクセスの場合はどうでしょうか。FFRPG でも更新および削除には UPDATE および DELETE 命令を使用します。
ネイティブ・アクセスは常にレコード単位ということは前回説明しました。
これは更新および削除の場合も同様です。SQL のように複数レコード同時更新や削除はできません。
ネイティブ・アクセスにおいて更新・削除を行う場合は、まず DCL-F usage でそれを指定しなければなりません。
前回の記事を思い出してください。
- USAGE(*UPDATE)
- USAGE(*DELETE)
では UPDATE 命令をもう少し詳しく見てみましょう。
更新対象ファイルの名前と、更新する値の入ったデータ構造は指定していますが、SQL の UPDATE で更新対象を特定する WHERE に相当する部分がUPDATE 命令には見当たりません。
つまり、UPDATE 命令単独では更新するレコードを特定できないのです。
そこで使用されるのがすでに説明したポインターです。
具体的には、更新するレコードに対して読み取り命令(READ / CHAIN など)を実行します。
これにより、更新および削除対象ファイルの場合は、後続の命令で更新および削除できるようになります。
更新削除対象ファイルの場合、読み取り命令によりポインターが位置づけられると、システムによりそのレコードがロックされます。
このロックにより、他のユーザーからは同じレコードを更新および削除目的で読み取ることはできなくなります。
このロックは、実際に更新および削除されるか、ポインターをずらす(SETLL / SETGT や他のレコードを読むなど)ことにより解除されます。
SQL との違いを整理しておきましょう。
SQL の場合は、対象レコードを特定するのは UPDATE および DELETE 命令であり実際の更新および削除とタイミングは同じです。
これに対し、ネイティブ・アクセスの場合は、対象レコードの特定と実際の更新および削除は別の命令を使用するので、その間にタイムラグが発生します。
基本的には以下のようになります。
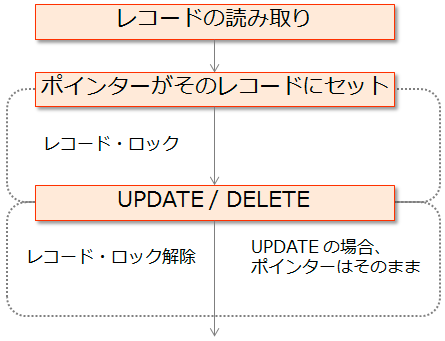 この読み取りと UPDATE / DELETE の間にはもちろん別の命令を記述しても構いません。
この読み取りと UPDATE / DELETE の間にはもちろん別の命令を記述しても構いません。その間は他のユーザー(プログラム)が、対象のレコードを更新および削除することをシステムが防いでくれます。
更新の場合は、まず更新するレコードを特定し、その後で更新するフィールドの値をセットし、その後 UPDATE 命令を実行します。
DELETE 命令は、オプションで検索引数を指定することができます。
この検索引数を指定することで、事前の読み取り命令を行わなくてもレコードを削除することも可能です。
では、更新、削除それぞれサンプル・プログラムを通して理解を深めましょう。
icafe017 プログラム(レコードの更新)
更新対象ファイルは以下のように記述します。この指定により、レコードを読み取るとそのレコードが更新目的でシステムによりロックされ、他のユーザー(プログラム)からの更新および削除から保護されます。
レコードの読み取りは通常どおり、READ / CHAIN 等の命令で行います。
読めたか読めなかったかにより、そのレコードを更新できるかどうかが決まります。
UPDATE 命令はレコード様式名に対して実行しなければなりません(外部記述ファイルの場合)。
ファイル名を指定するとコンパイル・エラーになるので注意しましょう。
データ構造は、更新対象のレコードを構成するすべてのフィールドを含んでいなければなりません。
通常は LIKREC キーワードを使用した DCL-DS で定義すると思います。
今回は定義するデータ構造を CHAIN でも使用するので、2番目のパラメータには *ALL を指定してください。
読み取り命令と更新命令で同じデータ構造を使用すれば、更新したいフィールドのみセットすれば良いので便利ですね。
それでは更新のサンプル・プログラムを見てみましょう。
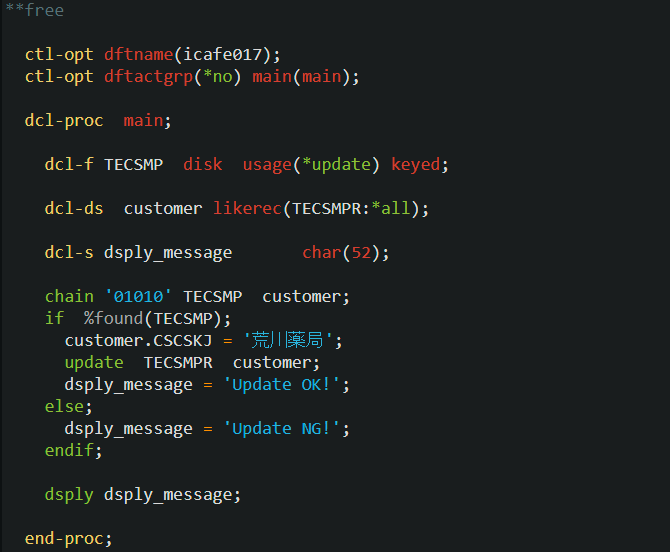 まず、使用するファイルを更新目的(*UPDATE)で定義し、得意先コードが ‘01010’ のレコードを CHAIN で検索しています。
まず、使用するファイルを更新目的(*UPDATE)で定義し、得意先コードが ‘01010’ のレコードを CHAIN で検索しています。レコードが存在すると %FOUND() 関数は true を返し、’01010′ のレコードにポインターがセットされて、システムがレコードをロックします。
その後、CHAIN で使用したデータ構造 customer の得意先名(customer.CSCSKJ)のみ値を変更(それ以外のフィールドは CHAIN で読んだときの値をそのまま使用)したあとで、UPDATE を実行しています。
基本的にロックを獲得したレコードの更新なので、更新できたかどうかは判断していません。
ではこのプログラムを作成して値が更新できるかどうかを確認してみましょう。
得意先名は自由に設定してください。
確認方法は、第5回の記事の icafe010 プログラムを参考にしてください。
icafe018 プログラム(レコードの削除1)
レコードの削除も、削除することを対象ファイルに指定しなければなりません。ではサンプル・プログラムを見てみましょう。
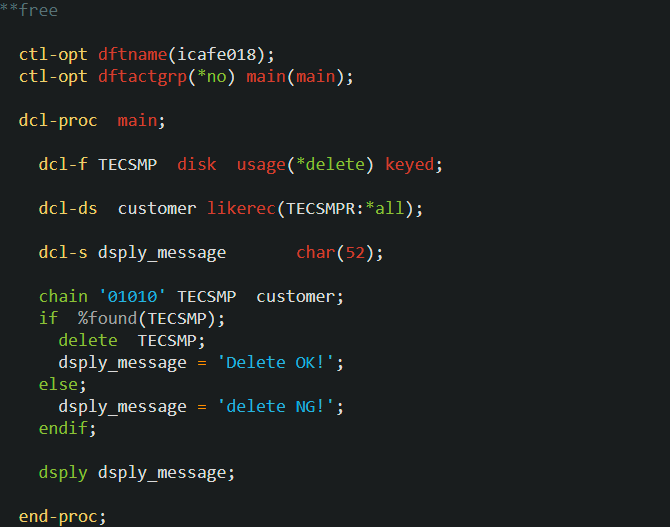 DELETE 命令は、ファイル名でもレコード様式でもどちらでもかまいません(外部記述ファイルの場合)。
DELETE 命令は、ファイル名でもレコード様式でもどちらでもかまいません(外部記述ファイルの場合)。今回は ‘01010’ のレコードを CHAIN で検索し、存在すればそのレコードを削除しています。
ではこのプログラムも作成および実行して削除できたか確認してみましょう。
icafe019 プログラム(レコードの削除2)
削除処理は、DELETE 命令で対象レコードを特定する情報を検索引数に指定して、直接削除することもできます。もちろん、指定した検索引数に該当するレコードが存在しなければ DELETE は実行されません。
その判断は DELETE 命令の直後の %FOUND() 関数により判断してください。
ではプログラム全体を確認して、作成および実行してみましょう。
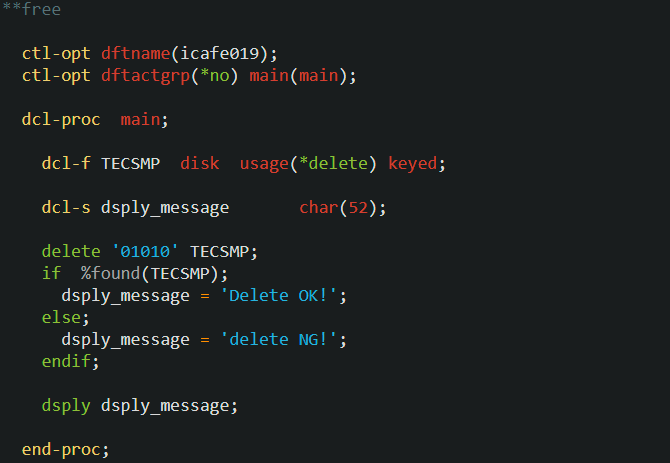 ‘01010’ のレコードは、icafe018 で削除しているので、そのまま icafe019 を実行すると ‘delete NG!’ とジョブ・ログに表示されます。
‘01010’ のレコードは、icafe018 で削除しているので、そのまま icafe019 を実行すると ‘delete NG!’ とジョブ・ログに表示されます。メニューの 10番「TECSMPデータの初期化」を実行して、プログラムを実行および結果の確認をしてください。
icafe020 プログラム(レコードの追加)
では最後にレコードの追加について解説します。レコードの追加も、DCL-F て定義する対象ファイルに対して USAGE で追加することを指定します。
ファイル名の場合はコンパイル・エラーになります。
WRITE 命令もレコード単位なので、当然ですがそのレコードを構成する全フィールドの値をセットする必要があります。
そのため、LIKEREC キーワードを使用した DCL-DS でデータ構造を定義するのですが、LIKEREC キーワードの第二パラメータには *OUTPUT もしくは *ALL を必ず指定するようにしてください。
WRITE 命令の場合は、追加できたかどうかは、WRITE 命令そのものが正常終了したかどうかで判断します。
この点が UPDATE / DELETE 命令と異なるところです。
では命令そのものが正常に終了したかどうかはどのように判断するのでしょうか。
RPG の命令には命令コード拡張を指定できるものがあります。書き方は以下の通りです。
エラーが発生したかどうかの判断は %ERROR() 関数を使用します。
もし、(e) を指定せず実行した WRITE 命令が異常終了(重複キーのエラーなどでレコードが追加できなかったなど)した場合は、RPG の例外処理ルーチンに制御が渡され、結果的にプログラムが異常終了するケースがあるので注意しましょう。
もうひとつ、今回は CLEAR 命令を使用しています。
データ構造のすべてのサブ・フィールドは、プログラム開始時は X’40’(ブランク)がセットされています。これは数値サブ・フィールドに対しても同じです。
この数値に X’40’ がセットされている状態で WRITE 命令を実行すると、対象となる数字フィールドをブランクで更新することになります。
システムは数値フィールドに数値以外がセットされたかどうかをチェックし、数値でなければ10進データ・エラーを発生させ WRITE 命令を異常終了させます。
CLEAR 命令は、データ構造に対して実行すると、数値データは 0 で初期設定するため、WRITE の直前に実行することで 10進データ・エラーを回避することができるのです。
今回使用するテーブルのフィールドはすべて文字タイプなのでこのエラーは発生しませんが、使い方も含めてあえて CLEAR を入れてあります。
それでは、プログラムの全体を確認しましょう。
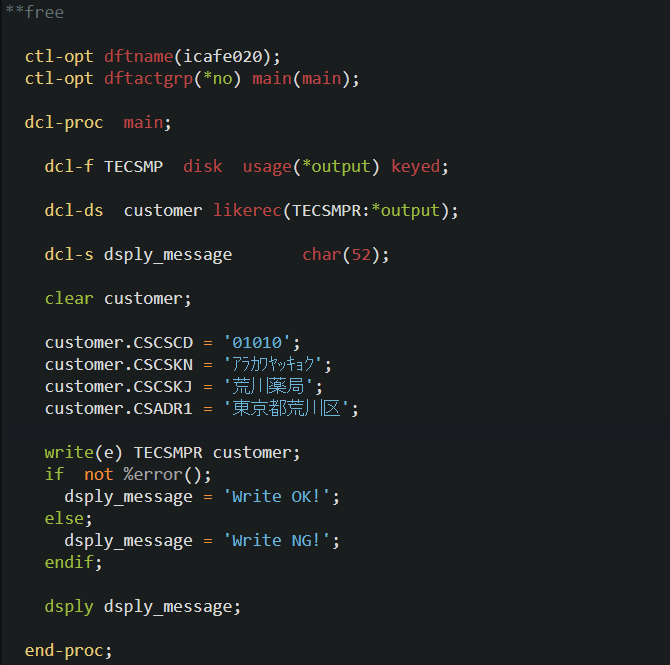 icafe019 で削除したレコードがこのプログラムで追加されるはずです。
icafe019 で削除したレコードがこのプログラムで追加されるはずです。このプログラムを2回実行すると、同じキーのレコードの追加になり重複エラーが発生しますが、命令コード拡張と %ERROR() によりこのエラーが処理され、’Write NG!’ のメッセージがジュブ・ログに書き出されるはずです。
いかがでしたか。
終わりに
ポインターの操作と、ファイルへのレコードの追加、更新および削除について解説しましたがいかがでしたか。ネイティブ・アクセスは SQL とは書き方が異なり、この連載で RPG を初めて触る方にとってはまだまだ難しいと感じるところがあると思います。
SQL とネイティブ・アクセス、どちらが良いとか悪いとかではなく、それぞれの長所を生かしてプログラミングができるのが RPG の良さなので、それぞれの書き方の基礎をしっかり身につけて今後のプログラミングに生かしてください。
IBM i の標準機能である DB2 for i を、自由自在にプログラムで扱うことができるようになれば、IBM i への理解もぐっと深まると思います。
これまでのプログラムは、実行結果はすべてジョブ・ログに出力して確認するというものでしたが、次回は結果を印刷および直接画面に出力する方法について解説する予定です。
どうぞお楽しみに!
著者プロフィール









