

[自習環境の登録申込の受付最終日:2026年2月26日(木曜日)]
詳細はこちら
前回の復習
「第五回 データベース – SQL(更新・削除・追加プログラム)」では、データベースに対する更新・削除および追加を SQL を使用して行う方法を解説しました。SQL をご存知の方は、RPG 言語を使用した IBM i のデータベース操作を違和感なく理解できたのではないかと思います。SQL を組み込んだ FFRPG を使用して、様々な技術者が IBM i のシステム開発にどんどん参加してくれることを願っています。 第四回で触れましたが、RPG 言語のデータベース・プログラミングは SQL の他にネイティブ・アクセスという方法があります。これは SQL が IBM i で使用できるようになる前から利用されてきた、IBM i における DB2 for i への基本的なアクセス方法です。SQL とかなり異なる書き方になるので、今回と次回の二回に渡ってじっくり解説していきたいと思います。この手法もぜひマスターしてください。ネイティブ・アクセス
ではまず、SQL によるアクセスとネイティブ・アクセスの違いを説明します。SQL は対象となるレコードを抽出するために WHERE で条件を指定しました。この条件により処理対象のデータが1レコードに限定されることもあれば、複数レコードとなる場合もあります。この特徴を生かして、ある条件に該当する複数レコードを同時に更新したり削除したりする時には SQL を使用すると便利です。 これに対して、ネイティブ・アクセスは常にレコード単位のアクセスを行います。SQL のような複数レコードを同時に処理することはできません。レコードを更新および削除する時も、常に1レコード毎にステートメントを使用して行います。このため場合によっては SQL よりコードが複雑になることもあります。しかし、細かなレコード単位の処理を行うことが必須である SoR システム構築には最適な方法であり、IBM i の既存のプログラムは殆どがネイティブ・アクセスで実装されています。 DB2 for i のデータベース・ファイルは、このレコード単位でのアクセスを可能とするために、アクセス・パスと呼ばれる仕組みが実装されています。アクセス・パスは以下の2種類です。- 到着順アクセス・パス 到着順アクセス・パスは、文字通りファイルにレコードが追加された順番を記録しているもので、その順番を相対レコード番号にシステムが自動的に採番して割当てていきます。データベースにアクセスする際にこの到着順アクセス・パスを使用することで、記録された順番でレコードを取り出すことができるようになります。
- キー順アクセス・パス もうひとつのアクセス・パスはキー順アクセス・パスと呼ばれます。DB2 for i ではファイルを作成する際にキー・フィールドを指定することができますが、このキーの値と相対レコード番号の対応表がこのキー順アクセス・パスです。キー順アクセス・パスはキーの値によって並んだ表なので、これをプログラムで使用することにより、到着順ではなくキーの並び順でレコードを取り出すことができます。また、特定のキーの値のレコードを直接取り出すことも可能になります。
ポインターについて
プログラムはどちらかのアクセス・パスを使用するように設定します。データベース・ファイルがオープンされると、アクセス・パスの先頭にポインターが設定されます。このポインターの役割は、直前にアクセスしたレコードの位置をアクセス・パス内で記憶することにあります。後ほど照会するレコード・アクセスのステートメントで詳細を解説します。ネイティブ・アクセスでは、条件にあうキー順アクセス・パスとポインターを使ってキーの順番通りにレコードを取り出すことも、ランダムにアクセスすることも自由に操作可能です。ファイル定義
それではネイティブ・アクセスを行うのに必要なステートメントを紹介していきます。まずファイルをネイティブ・アクセス処理するには、プログラムで使用するファイルを DCL-F ステートメントで定義しなければなりません。 DISK キーワードは、このファイルがデータベースであることを示しています。このキーワードはファイル名の直後に指定しなければなりません。
USAGE キーワードは、プログラム内でのファイルの使用方法を指定します。指定した方法以外の使用はできないので注意しましょう。たとえば、
DISK キーワードは、このファイルがデータベースであることを示しています。このキーワードはファイル名の直後に指定しなければなりません。
USAGE キーワードは、プログラム内でのファイルの使用方法を指定します。指定した方法以外の使用はできないので注意しましょう。たとえば、
- USAGE(*INPUT)
- データベース・ファイル
- 入力専用
 どの書き方が良いのかはそれぞれで判断していただければと思いますが、個人的にはプログラムの可読性を考えて、省略値もすべて記述するほうが良いのではと思います。
DCL-F は、最初のプロシージャー定義(main サブ・プロシージャー)の前と、サブ・プロシージャー内の2箇所で記述することができます。前者で定義するとグローバル・ファイル、後者はローカル・ファイルと言います。
どの書き方が良いのかはそれぞれで判断していただければと思いますが、個人的にはプログラムの可読性を考えて、省略値もすべて記述するほうが良いのではと思います。
DCL-F は、最初のプロシージャー定義(main サブ・プロシージャー)の前と、サブ・プロシージャー内の2箇所で記述することができます。前者で定義するとグローバル・ファイル、後者はローカル・ファイルと言います。
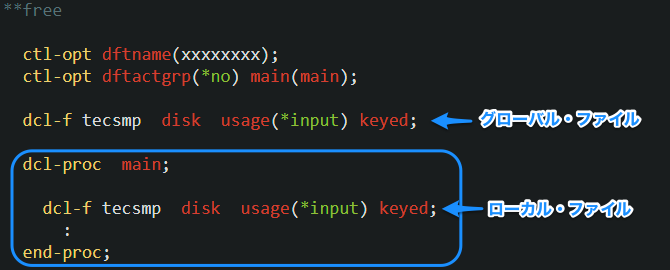
ローカル・ファイル
マニュアルには「ローカル・ファイルに対する入出力は、データ構造を使用することによってのみ実行できます。」と記述があります。この意味を説明します。 組込 SQL では、対象フィールドを SELECT の直後に指定し、取得したフィールドの値は事前に用意したホスト変数にセットされました。これに対しDCL-F で定義したファイルでは、レコードを読み取ると基本的に全てのフィールドの値が取得され、値は読み取り命令で指定したデータ構造にセットされます。つまり「データ構造を使用する」とは、このアクセスによって取得された全フィールドの値が、ホスト変数ではなく指定したデータ構造にのみセットされるということです。このデータ構造はプログラムで事前に定義しておく必要があります。 グローバル・ファイルの場合は、RPG コンパイラーがレコードの各フィールドの値を保存するための変数を自動的に用意します。データベース・ファイルはファイル自身にレコードを構成するフィールドの定義を持っています(これを外部記述という)ので、コンパイラーはその値を参照し、その定義を使って I 仕様書(入力仕様書)を自動で生成するのです。この I 仕様書は、読み取ったレコードのフィールド構成を記述するもので、定位置記入形式ではプログラマーが記述可能ですが、FFRPG では使用できません。しかし、コンパイラーは内部的に使用できるためこれが可能なのです。 それに対して、サブ・プロシージャー内では I 仕様書は使用することができないため、コンパイラーがローカル・ファイルの外部記述を使用して変数を自動的に用意することができません。そのため、プログラマーがデータ構造を事前に用意しておかなければならないのです。スコープについて
グローバル・ファイルは、すべてのサブ・プロシージャーから参照することができます。取得した値を保存する変数には静的記憶域が使用されるため、プログラムが実行されている間存在しています。ファイルのオープンは基本的にプログラムの開始時点で自動的に行われます。 ローカル・ファイルは、それを定義したサブ・プロシージャー内でのみ参照可能です。サブ・プロシージャーが開始されるとファイルは自動的にオープンされ、RETURN 命令もしくは最後のステートメントが実行されたあとでサブ・プロシージャーが終了すると自動的にクローズされます。入出力で使用するデータ構造をサブ・プロシージャー内で定義すると自動記憶域が使用されるため、プロシージャーが終了するとそのデータ構造も破棄されます。 (参考)STATIC キーワードを使用することにより、静的記憶域に関連付けることも可能です。 それでは、実際のプログラムを通して、ネイティブ・アクセスの基本を理解していきましょう。icafe013 プログラム(ランダム検索)
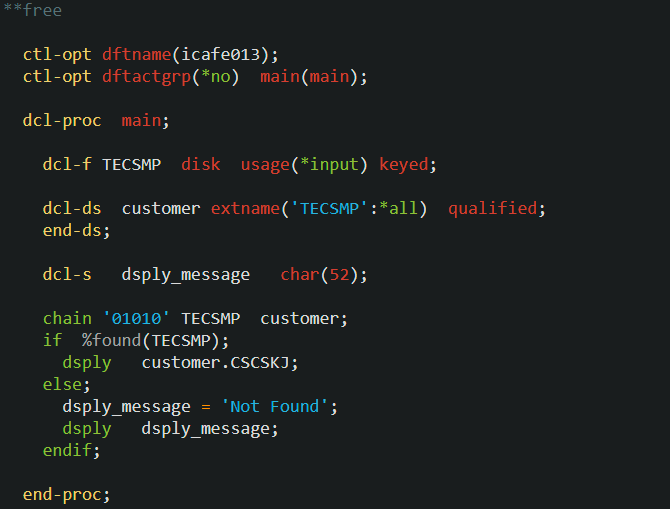
最初は icafe004.sqlrpgle と同様の処理をネイティブ・アクセスで作成します。まずはファイルの定義と使用するデータ構造の定義を見ていきましょう。 DCL-F ステートメントを使用して TECSMP ファイルを定義しています。TECSMP ファイルは得意先コード(CSCSCD)がプライマリー・キーとして定義されており(第四回参照)、そのキーを使ってアクセスするために KEYED キーワードを指定しています。また、プログラム内ではレコードの読み取りしか行わないので USAGE キーワードで *INPUT を指定しています。
読み取ったレコードのフィールドの値を保存するためのデータ構造を DCL-DS で定義します。今までと異なるのは、extname キーワードの2番目のパラメータに *INPUT を指定している点です。指定できるパラメータの値は以下の通りです。
DCL-F ステートメントを使用して TECSMP ファイルを定義しています。TECSMP ファイルは得意先コード(CSCSCD)がプライマリー・キーとして定義されており(第四回参照)、そのキーを使ってアクセスするために KEYED キーワードを指定しています。また、プログラム内ではレコードの読み取りしか行わないので USAGE キーワードで *INPUT を指定しています。
読み取ったレコードのフィールドの値を保存するためのデータ構造を DCL-DS で定義します。今までと異なるのは、extname キーワードの2番目のパラメータに *INPUT を指定している点です。指定できるパラメータの値は以下の通りです。
 「入力可能フィールド」と「出力可能フィールド」という表現に違和感を覚える方がいらっしゃるかもしれません。データベースのフィールドは入力も出力もできるのが当たり前ですよね。しかし、データベース以外のファイルには「入力しかできないフィールド」や「出力しかできないフィールド」を定義できるものがあります。データ構造内に含めるフィールドをそういった視点で限定したい場合のオプションと考えてください。今回は読み取るだけなので *INPUT を指定していますが、*ALL も指定可能です。
それでは実際のレコードを読み取るステートメントを解説しましょう。
「入力可能フィールド」と「出力可能フィールド」という表現に違和感を覚える方がいらっしゃるかもしれません。データベースのフィールドは入力も出力もできるのが当たり前ですよね。しかし、データベース以外のファイルには「入力しかできないフィールド」や「出力しかできないフィールド」を定義できるものがあります。データ構造内に含めるフィールドをそういった視点で限定したい場合のオプションと考えてください。今回は読み取るだけなので *INPUT を指定していますが、*ALL も指定可能です。
それでは実際のレコードを読み取るステートメントを解説しましょう。
 それではこのソースを Orion で登録してコンパイルしてみましょう。今回は SQL を含んでいないので、ソースの拡張子は rpgle です。コンパイルも実習メニューのオプション 1 を使用してください。そのため、CTL-OPT で dftname キーワードを指定している点に注意してください。
実行するとジョブログに「荒川薬局」と表示されるはずです。うまくできましたか?
それではこのソースを Orion で登録してコンパイルしてみましょう。今回は SQL を含んでいないので、ソースの拡張子は rpgle です。コンパイルも実習メニューのオプション 1 を使用してください。そのため、CTL-OPT で dftname キーワードを指定している点に注意してください。
実行するとジョブログに「荒川薬局」と表示されるはずです。うまくできましたか?
icafe014 プログラム(ランダム検索:LIKEREC)
icafe013 ではデータ構造の定義で extname キーワードを指定しましたが、別のキーワードを指定して定義することも可能なのでそれを紹介しましょう。 さきほどファイル自身がフィールドの定義を持っているという話をしました。ファイルにはこの各フィールドの定義の他に、フィールドで構成されるレコードの名称も定義されています。この名称のことをレコード様式名といいます。DCL-F ステートメントでファイルを定義すると、このレコード様式名も RPG プログラム内で使用することができます。 DCL-DS ステートメントでは、このレコード様式を参照するために likerec キーワードが使用可能です。今回参照している TECSMP のレコード様式名は TECSMPR なので、これを使用してデータ構造を定義するには以下のようなコーディングになります。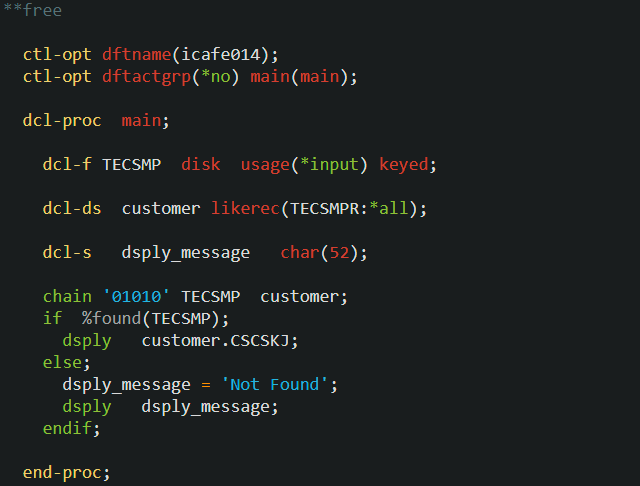
icafe015 プログラム(次のレコードの読み取り)
前回、SQL でカーソルを定義して fetch ステートメントで1件ずつレコードを取得するプログラムを作成しましたが、同様のプログラムをネイティブ・アクセスで作成してみましょう。 ネイティブ・アクセスの場合、サブ・プロシージャーが開始するとファイルが自動的にオープンされると説明しました。このオープンと SQL の「カーソル定義 + オープンステートメント」は同じと考えてください。つまり、ネイティブ・アクセスの場合は SQL のカーソル定義と同様の操作は必要ないということです。 SQL の fetch ステートメントに相当する読み取りステートメントは READ です。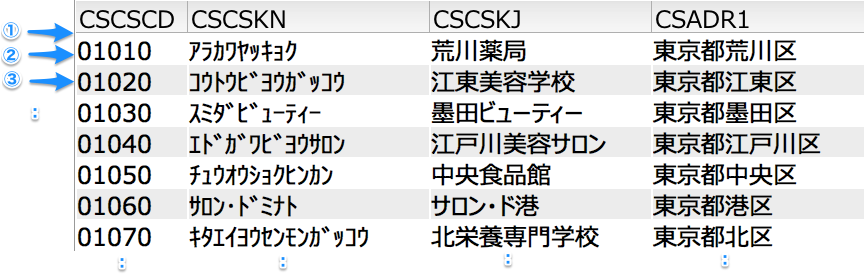 青い矢印がポインターだと仮定してください。まず、main プロシージャーが実行されると TECSMP がオープンされ、ポインターが最初のレコードの先頭に位置づけられます(①)。READ ステートメントは「次のレコードの読み取り」です。この「次」とは現在ポインターが位置づけられている「次」の意味です。最初の READ が実行されると①の次、つまり最初のレコードにポインターが移動して(②)そのレコードが読み取られます。その後また READ が実行されるとポインターが次のレコードに移動して(③)そのレコードが読み取られます。
ポインターが移動してレコードが読めたかどうかの判断は、%eof 関数を使用します。
青い矢印がポインターだと仮定してください。まず、main プロシージャーが実行されると TECSMP がオープンされ、ポインターが最初のレコードの先頭に位置づけられます(①)。READ ステートメントは「次のレコードの読み取り」です。この「次」とは現在ポインターが位置づけられている「次」の意味です。最初の READ が実行されると①の次、つまり最初のレコードにポインターが移動して(②)そのレコードが読み取られます。その後また READ が実行されるとポインターが次のレコードに移動して(③)そのレコードが読み取られます。
ポインターが移動してレコードが読めたかどうかの判断は、%eof 関数を使用します。
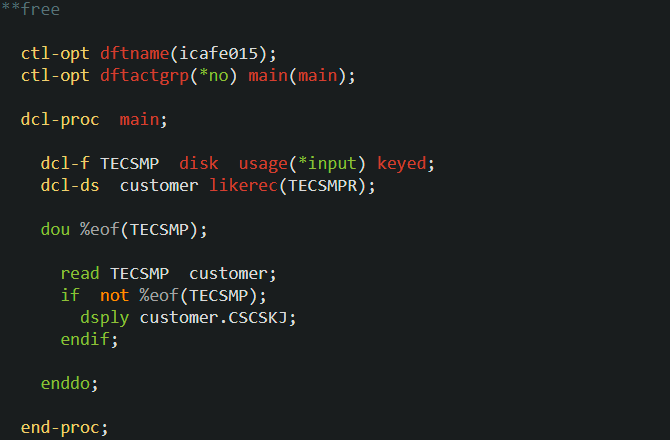 dou %eof(TECSMP) は、「TECSMP」の次のレコードが read できなくなるまで繰り返すという意味です。また、今回のサンプルでは likerec キーワードの2番目のパラメータは指定していませんが、この場合は省略値として *input が使用されます。
前回の icafe009.sqlrpgle と比べてみてください。ネイティブ・アクセスではカーソルの定義やオープン、クローズもなく読みやすいコードになっていると思います。このプログラムを icafe015.rpgle として登録し、コンパイルして実行してみましょう。
dou %eof(TECSMP) は、「TECSMP」の次のレコードが read できなくなるまで繰り返すという意味です。また、今回のサンプルでは likerec キーワードの2番目のパラメータは指定していませんが、この場合は省略値として *input が使用されます。
前回の icafe009.sqlrpgle と比べてみてください。ネイティブ・アクセスではカーソルの定義やオープン、クローズもなく読みやすいコードになっていると思います。このプログラムを icafe015.rpgle として登録し、コンパイルして実行してみましょう。
終わりに
いかがでしたか。SQL とは異なる DB2 for i へのネイティブ・アクセスのコーディングは少し難しいと感じられたかもしれません。しかし、このネイティブ・アクセスは、IBM i が AS/400 として発表された 30年前から(厳密にはその前から)、OS に組み込まれたデータベースに RPG からアクセスする方法として使われてきましたし、現在もほとんどのプログラムがこの方法で記述されています。この手法を理解することにより、既存のプログラム資産の理解も深まることでしょう。 今回は READ のところでポインターを紹介しましたが、次回はこのポインターの操作方法を使ったより具体的な読み取り操作を解説します。また、データの更新、削除および追加についても解説する予定です。 どうぞお楽しみに!著者プロフィール










