
 「心地よいデータマイニング3 つの掟」と題し、データマイニングの定義にはじまり、ビジネスへの応用、アルゴリズムの解説まで全10回にわたる、データアナリティクスについての連載です。第6回目となる今回は、「マイニングアルゴリズムを簡単に解説 その2」と題し、そのポイントを解説します。
アルゴリズムは数式まで理解や探求をする必要はありませんが、代表的なものについてはその概要を知っておくことは大切です。
詳細まで踏み込んでいくと、解釈できない数式が出てきたりして、アルゴリズムは複雑なものと感じてしまいますが、当コラムで最初から書いているとおり、ビジネスや企業を成長させるためにはアナリティクスはとても重要です。従って、アウトプットされた結果を「このアルゴリズムを使ってマイニングを実行したのでこうなった」という具合に、それらを理解できるレベルの知識は持っていたいものです。そして、そこで初めて各企業とその現場において、マイニングやアナリティクスが身近になり、役に立っていくのではないかと思います。以下の図は、前回第5回でご紹介しました、3つの分析アプローチ方法です。
「心地よいデータマイニング3 つの掟」と題し、データマイニングの定義にはじまり、ビジネスへの応用、アルゴリズムの解説まで全10回にわたる、データアナリティクスについての連載です。第6回目となる今回は、「マイニングアルゴリズムを簡単に解説 その2」と題し、そのポイントを解説します。
アルゴリズムは数式まで理解や探求をする必要はありませんが、代表的なものについてはその概要を知っておくことは大切です。
詳細まで踏み込んでいくと、解釈できない数式が出てきたりして、アルゴリズムは複雑なものと感じてしまいますが、当コラムで最初から書いているとおり、ビジネスや企業を成長させるためにはアナリティクスはとても重要です。従って、アウトプットされた結果を「このアルゴリズムを使ってマイニングを実行したのでこうなった」という具合に、それらを理解できるレベルの知識は持っていたいものです。そして、そこで初めて各企業とその現場において、マイニングやアナリティクスが身近になり、役に立っていくのではないかと思います。以下の図は、前回第5回でご紹介しました、3つの分析アプローチ方法です。

図1:3つの分析アプローチ方法 (前回掲載)
今回はこの図の中の「予測」でよく使われる決定木のアルゴリズムについて易しく解説します。決定木分析とは
ディシジョンツリーとも言われ、マイニングの対象となるデータを属性変数または数値から分類し、これを繰り返し(深堀りしていく)その状態を樹形図で表現するものです。以下のような図を樹形図と呼びます。幹からはじまり、枝が分岐する形になります。内容は、第5回に引き続き、洋菓子店のデータを分析した例にしています。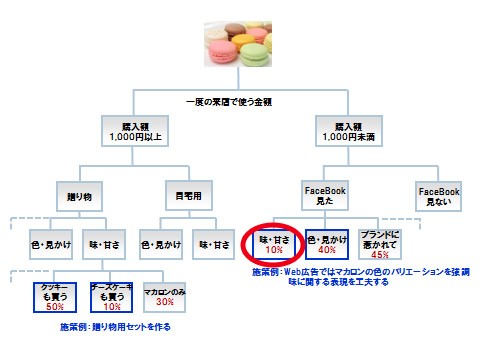
図2:マカロンを買うお客様分析①
マイニング対象となるデータに対して決定木分析を行い、「マカロンを買ったお客様で、一回の来店でたくさん買い物をしていただいたお客様にはどういった傾向があるのか」を深堀りします。そういう意味ではBIツール(第1回)のドリルダウンと似た部分があります。 この例の場合は、購買データとアンケートデータの両方を活用してマイニングしています。アンケートについては、色や見かけ、ブランドなどを重要視するか否かをお客様に聞いています。 まずはじめは、1回の来店時に購入した金額で分岐するところからはじまります。FaceBookをきっかけとして来店したお客様は、色や見かけ、ブランドといったイメージを気にして来店しています。 この場合はお試し感覚で購入しているのか、購入金額は高くありません。しかし、今後ロイヤルカスタマーに成長する可能性があります。また、味・甘さなど味覚に関する表現はWeb上では口コミなどである程度知りうることはできますが、そこを重要視するお客様は少ないようです。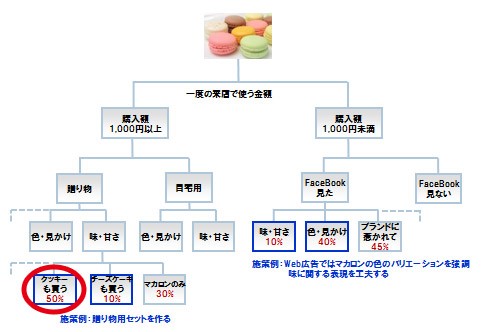
図3:マカロンを買うお客様分析②
決定木分析のアルゴリズム
決定木分析は自動的に対象データを分類していくものです。まずは、データ全体を最もよく分類できる属性変数(*1)を探して、その分類されたデータの中で最もよく分類できる属性変数を探して…と繰り返していきます。そしてこれ以上分類できないところまで繰り返します。 このアルゴリズムには種類があります。CHAID、C&R Tree、C5.0、QUESTなどが有名です。IBM SPSS Modelerにもこれらのアルゴリズムが採用されていますではどういう理屈で属性変数を見つけ出し、枝 (Tree)を作っていくのでしょうか。 例えばCHAIDの場合は、「カイ2乗統計値」を使って最適な分類・分岐を行います。まずこのアルゴリズムは、「数式」、「カイ2乗分布表」、「自由度」の3つの要素から構成されます。① 数式
「カイ2乗統計値」を求めるには「カイ2乗検定」という方程式を使用し、データを計算します。数式は以下です。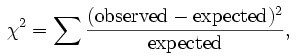 つまり、「実績値から期待値を引いたものを2乗し、それを期待値で割る。」という数式です。そして対象となる要素の数分のカイ2乗検定値を合計(Σ)したものが、カイ2乗統計値です。
つまり、「実績値から期待値を引いたものを2乗し、それを期待値で割る。」という数式です。そして対象となる要素の数分のカイ2乗検定値を合計(Σ)したものが、カイ2乗統計値です。
② カイ2乗分布表 (参照するテーブル)(*2)
カイ2乗統計値を以下の表に当てはめ、有意水準値0.05以下であれば分析対象となった要素同士に差異は無いと解釈されます。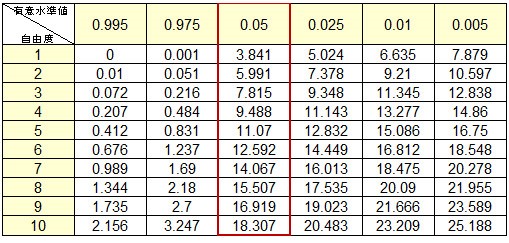
図4:カイ2乗分布表










