「心地よいデータマイニング3 つの掟」と題し、データマイニングの定義にはじまり、ビジネスへの応用、アルゴリズムの解説まで全10回にわたる、データアナリティクスについての連載です。第5回目となる今回は、「マイニングアルゴリズムを簡単に解説 その1」と題し、そのポイントを解説します。
データマイニングの3つの分析アプローチ方法
アルゴリズムについては、長年研究されて確立されたその計算式までの理解は必須ではありません。しかし、データマイニングを行うにあたり、代表的なアルゴリズムの名称や「何をするもの」程度の理解や把握はしておいたほうがよいでしょう。データマイニングにおけるアルゴリズムには本当にたくさんの種類がありますが、分析アプローチ方法は大きく3つに分類されます。
- 分類
例えば似たような顧客グループや商品グループを見出し、商品製作やDM等の施策に役立てる。(クラスター分析など)
- 予測
過去のデータから最適なモデルを算出させ、将来を確率付きで予測 (決定木分析など)
- パターン発見
蓄えられた膨大なデータからパターンやルールを発見し、将来を確率付きで予測(アソシエーション分析、マーケットバスケット分析 (*1)など)
 図1:3つの分析アプローチ方法 (*2)
図1:3つの分析アプローチ方法 (*2)
まず、分類でよく使うクラスター分析を解説します。
*1:顧客の買い物カゴの中身を分析し、購買における併売傾向などの相関性を探り出す、データマイニングの代表的な分析手法。この分析を行うアルゴリズムにも複数種類存在する。代表的なものは次回以降で解説。
*2:IBM SPSS Modeler資料より
クラスター分析
クラスター(cluster)は、英語で「房」「集団」「群れ」を意味します。葡萄の房もクラスターと表現されます。IT業界では「クラスターサーバー (*3)」という言葉で耳馴染みがあるでしょう。データマイニングにおいて、このクラスター分析は、異なる性質のものが混在しているデータの中で、お互いに似通ったものをあつめて「集団」を作り分類するものです。
分類したあとは、その集団の持つ傾向や意味を見出し、ビジネスに展開していきます。クラスター分析は、データを「階層化して集団化する」か「階層化せずに集団化する」かの違いで、2種類の方法に分けられます。「階層クラスター分析「と「非階層クラスター分析」です。
階層クラスター分析
階層クラスター分析とは、対象データを最も似ているものから順に並べ、最終的にはひとつのクラスターになるようクラスター化を進めるものです。以下で図とサンプル例で解説します。
この例は、洋菓子店でお客様にアンケートを行ったサンプルです。お客様に購入した商品を選んだ理由を聞いています。また、回答は複数選択可能とします。そして、その結果としてまずは図2のような集計がなされます。
 図2:洋菓子店アンケート傾向集計表
図2:洋菓子店アンケート傾向集計表
それを階層クラスター分析すると、図3のような図がアウトプットされます。この図をデンドログラムと言います。
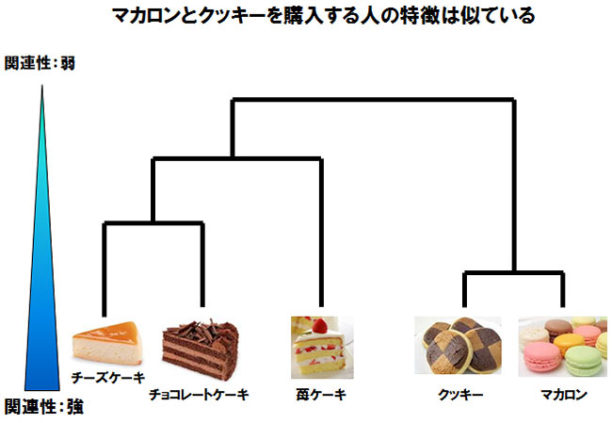 図3:洋菓子店の階層クラスター分析
図3:洋菓子店の階層クラスター分析
デンドログラムは要素同士の関連性の強い順に、樹形図で視覚的にわかりやすく描くものです。下部に位置するほど強い関連性があり、この例の場合はアンケートの回答内容に類似性が高いということになります。最も似た傾向を持つのはクッキーとマカロンを購入したお客様ということがわかります。例えばマカロンを買いに来たお客様にクッキーをお勧めすると同時に買ってくれるかもしれません。これは購入した結果の併売分析(先に書いたマーケットバスケット分析)ではなく、アンケート結果の分析から併売の可能性を見出せる例です。
この分析手法は直感的でわかりやすいアウトプットを得ることができます。しかしながら、クラスターの数(分類の対象)が多くなると、計算量が多くなる短所があります。
非階層クラスター分析
この手法は類似するデータを自動でグルーピングするアルゴリズムです。最もよく使われるk-meansアルゴリズムについて解説します。これはIBM SPSS Modelerにも実装されています。非階層クラスター分析は、大まかには以下のようなステップで行います。
- クラスターの数を設定(この例では3つ)
全データの中でサンプルデータ(シードと言います)をランダムに選び、それに近いデータをあつめて3つのクラスターを仮に形成
- シードと他のデータを比べクラスター内の中心(重心)を決め、その重心を新しいシードとする
- 新しいシードと他のデータを比べクラスターを再編成(反復)
という流れです。もう少しステップを細かく分割して図で解説します。
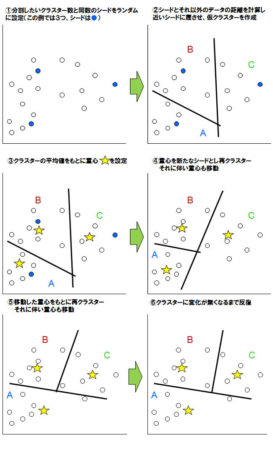 図4:非階層クラスター分析のステップ
図4:非階層クラスター分析のステップ
こうしてクラスタリング分析を行った結果として、各クラスターはその傾向や特徴が異なるものとして分類されます。また、階層クラスター分析で使用したアンケートデータで非階層クラスター分析を行ってみると、「味・甘さ」「フェイスブックを見て」「原材料」「ブランドに惹かれて」という回答を行ったお客様は同じクラスターに所属し、「贈り物に適切」「色や見かけ」「価格が手頃」という回答を行ったお客様は同じクラスターに所属するといったこともわかったりします。お客様の意識がいくつかの集団に分けられることが、ここからわかります。
どちらのクラスター分析を行うかは、目的によって異なるため、使い分けることが必要です。階層型クラスター分析は、ブランドや商品など視点定めてクラスター化したい場合に有効です。一方、非階層型クラスターは、データの階層化は関係なく、「いくつに分類するか」を決めてデータを分類するため、ランダムで大量なデータの傾向調査などに適しています。これはビッグデータを分析対象にする場合にも適している手法です。
今回はマイニングのアルゴリズムの解説第1弾ということで、クラスター分析について書きました。次回は「2.予測」でよく使われる決定木について解説しますのでお楽しみに。
*3:複数のコンピュータを連結し、利用者や他のコンピュータに対して全体で1台のコンピュータであるかのように振舞わせる技術。(IT用語辞典 e-Words)












