

1. はじめに
第10回では、ファイル転送におけるセキュリティー強化を主なテーマとして、「chrootの基本的な仕組みと役割」および「安全なファイル転送環境の構築方法」について解説しました。chrootは、特定のプロセスのルートディレクトリーを仮想的に変更可能で、指定されたディレクトリー以下のみを「システム全体」として認識させ、外部からのアクセスに対するセキュリティーの強化を実現します。
chrootを適切に使用することで、より堅牢な環境を構築し、管理者の負担を軽減できることを理解していただけたと思います。
第11回となる今回は、IBM i のLinux環境をさらに活用するための重要な要素である「シェルスクリプト」に焦点を当て、その基本と応用について解説します。
IBM i をLinux的に使う上で、シェルスクリプトを理解することは非常に重要です。これまで解説してきたssh、シェル、基本コマンド、OSSツールなどの知識と組み合わせることで、定型業務を効率化し、システムの運用管理を大幅に改善することが可能になります。今回の記事では、シェルスクリプトの基本構文から、データ転送やジョブスケジューリングといった具体的な例を通じて、その効果を実感できるでしょう。以下の内容を中心に解説します。
- シェルスクリプトの基本概念
- シェルスクリプトを使用したファイルのバックアップやログ解析
- ジョブスケジュールでシェルスクリプト実行を自動化
今回の記事を通じて、Linux ユーザーの方には、IBM i 環境でのシェルスクリプト活用の可能性を感じていただけると思います。また、IBM i ユーザーの方にもシェルスクリプトを理解していただくことで、もしかすると今まで不可能と思ってきたことが実現できるかもしれないと、思っていただけたら幸いです。
それでは始めていきましょう。
2. シェルスクリプトの基本
IBM i の世界では、システムの管理やアプリケーションの実行は、全てCLコマンドを使用します。システム管理では、必要に応じて管理者がコマンドを実行することが多いですが、アプリケーションの実行においては、ジョブ・フローに基づき、一定の順序でプログラムを定期的に実行する必要があります。
この処理を毎回間違えることなく確実に実行するためには、プログラムの呼び出し順序や処理の分岐・繰り返しなどをあらかじめプログラム化し、自動的に実行できる仕組みが求められます。IBM i では、この役割を担うのがCLプログラムです。CLプログラムを作成することで、決められた手順に従った処理を自動化できます。ただし、CLコマンドを単に並べるだけではなく、プログラムとして実行するには、コンパイラーを使用して実行可能なプログラム・オブジェクトに変換する必要があります。
では、IBM i のCLプログラムと同様の役割を果たすLinuxやAIXの機能は何でしょうか。それが、「シェルスクリプト」です。
「シェル」とは「オペレーティングシステムのさまざまな機能を実行するために、ユーザーが使用するインターフェース」のことでしたね(第3回「シェルと基本コマンド」を参照)。シェルにはさまざまな種類があり、それぞれ使用できる命令に違いがあります。
「スクリプト」とは、もともと「台本」という意味ですが、コンピューターの分野では「何をどのように実行するか」を指示する命令のリストのことを指します。
シェルスクリプトは、それを実行するシェルがスクリプトの内容を読み込み、動的に実行するため、CLプログラムのように事前に実行可能な形式に変換する必要はありません。
今回は、第4回「OSS Part-1」で紹介したbashシェルを前提としたシェルスクリプトについて解説します。
シバンについて
前述したように、シェルスクリプトはシェルによって実行されます。スクリプト・ファイル名の拡張子に特に決まりはありませんが、慣習的に「.sh」が使用されることが多いため、この慣例に従うのが望ましいでしょう。これは、可読性や管理の観点からも適切です。
スクリプトを実行するには、使用するシェルの引数としてスクリプトファイルを指定します。例えば、bashでスクリプトファイル ./filexx.sh を実行する場合は、以下のように記述します。
-bash-5.1$ /QOpenSys/pkgs/bin/bash ./filexx.sh
もし、スクリプトファイルに実行属性があれば、ファイル名のみで直接スクリプトを実行することも可能です。
例えば、所有者に実行属性を与えるには、chmodの引数に、「u+x」(userに実行属性 x を + する)を渡します。
bash-5.1$ ls -l ./filexx.sh -rw-r--r-- 1 ogawa 0 75 Feb 23 08:41 ./filexx.sh -bash-5.1$ chmod u+x ./filexx.sh -bash-5.1$ ls -l ./filexx.sh -rwxr--r-- 1 ogawa 0 75 Feb 23 08:41 ./filexx.sh -bash-5.1$ ./filexx.sh (実行結果を表示)
ただ、ファイル名を直接指定して実行した場合、先ほどの例と違ってどのシェルが使われるかはわからない(どのシェルから呼び出されるかわからない)ので、場合によっては実行エラーとなる可能性もあります。これを防ぐために、シェルスクリプト内に使用するシェルを明示指定することも可能です。以下の例は、IBM i のPASE環境で使用されるシェルスクリプトの先頭の記述の例です。
#!/QOpenSys/pkgs/bin/bash
先頭の #! は「シバン」と呼ばれ、その後にこのスクリプトファイルを実行するシェルを指定します。実行属性が付与されたシェルスクリプトが指定されると、カーネルはこのシバンを読み取り、指定されたシェルにスクリプトファイルのパスを渡して実行します。
シバンが無くても、環境が整っていればスクリプトは実行可能ですが、どの環境でも確実に実行できるよう、常に指定すると良いでしょう。
これ以降のサンプル・コードでは、シバンに /QOpenSys/pkgs/bin/bash が指定されていることを前提に説明を進めます。
それでは、シェルスクリプトの基本的な文法事項を確認していきましょう。
変数
シェルスクリプトでは変数を使用できます。変数定義は「変数名=値」のように記述します。このとき、= の前後にスペースを入れてはいけません。これは、bash においてスペースがコマンドやオプション、引数を区切る役割を持つため、= の前後にスペースがあると変数への代入ではなく、別のコマンドとして解釈されてしまうためです。
var="Hello, World"
スクリプト内で変数を参照するには、変数名の前に $ を付けます。
var="Hello, World" echo $var
また、${変数名} と指定して参照することもできます。
name="ogawa"
echo $nameabc
echo ${name}abc
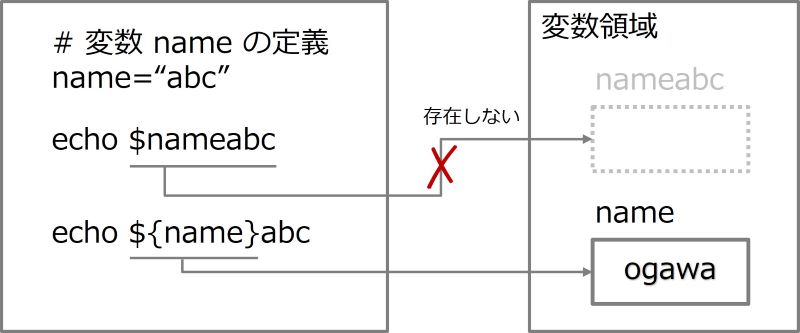
最初のechoでは、変数 nameabc は存在しないため、空文字が出力されます。しかし、2番目の例では、変数の値と文字列 abc が連結され、ogawaabc と出力されます。つまり、中括弧を使用することで、変数名の範囲を明確に示すことができるのです。スクリプトの可読性を高めるためにも、変数参照には中括弧をできるだけ使用しましょう。
文字リテラルと変数
「文字リテラル」とは、プログラム内で文字列としてそのまま扱われる値のことで、シングルクォート(’)かダブルクォート(”)で囲みます。
文字リテラルと変数を連結することは良くあり、その場合はダブルクォートで囲った文字リテラル内で、変数名を指定します。シングルクォートだと変数と見なされないので注意が必要です。
#!/QOpenSys/pkgs/bin/bash
VAR="abcdefg"
echo "変数 VAR の内容は ${VAR} です。"
echo '変数 VAR の内容は ${VAR} です。'
上記スクリプトの実行結果は、
変数 VAR の内容は abcdefg です。
変数 VAR の内容は ${VAR} です。
です。ダブルクォートで囲んだ場合、変数の値は展開されます(変数の値で置き換わる)が、シングルクォートの場合は変数とみなされず、文字リテラル「${VAR}」として扱われていますね。
配列
配列は以下のように定義します。
array=("Blue" "Red" "Yellow")
各配列の値を参照するには、配列名の後にブラケット(角括弧)を使い、要素数を指定します。要素数は 0 から始まる点に気をつけてください。
#!/QOpenSys/pkgs/bin/bash
array=("Blue" "Red" "Yellow")
echo ${array[0]}
上記スクリプトの結果は Blue が表示されます。
全ての要素を参照するには、ブラケット内に @ を指定してください。
#!/QOpenSys/pkgs/bin/bash
array=("Blue" "Red" "Yellow")
echo ${array[@]}
上記スクリプトを実行すると
Blue Red Yellow
と表示されます。
制御構造(if)
シェルスクリプトでは、if 文、for 文、while 文などを使用して、処理の流れを制御することができます。
条件によって処理を分岐させるには、if 文を使用します。
#!/QOpenSys/pkgs/bin/bash VAR="abcdefg" if [ $VAR = "abcdefg" ]; then echo "OK" else echo "NG" fi
条件式(if 文の直後)はブラケットで囲むことで、内部的に test コマンドが実行され、その結果として真(0)または偽(1)が返されます。基本的には、条件式はブラケットもしくはダブル・ブラケット(後述)を使用して記述するようにしましょう。
この書き方は、変数 var の値にスペースが含まれていない場合は正常に動作します。しかし、変数の値にスペースが含まれている場合、条件式内で値が展開された際にエラーが発生する可能性があるため、注意が必要です。
#!/QOpenSys/pkgs/bin/bash VAR="abc defg" if [ $VAR = "abcdefg" ]; then echo "OK" else echo "NG" fi
上記を実行すると、以下のエラーとなり処理が正しく実行されません。
line 5: [: abc: unary operator expected
これは、変数が展開された結果、条件式が以下のようになってしまうからです。
if [ abc defg = "abcdefg" ]; then
これを防ぐためには、変数をダブルクォートで囲む必要があります。
if [ "$VAR" = "abcdefg" ]; then
こうすると、展開後は
if [ "abc defg" = "abcdefg" ]; then
となり、正しく条件式が判定されます。あるいは、ダブル・ブラケットで囲むと、上記のような扱いにならないので通常はこちらのほうが良いかもしれません。
if 文に使用できる比較演算子は以下のとおりです。
| 数値比較 | 文字列比較 | 説明 |
|---|---|---|
| -eq | = | 等しい |
| -ne | != | 等しくない |
| -gt | < | より大きい |
| -ge | 以上 | |
| -lt | > | より小さい |
| -le | 以下 | |
| -z | 文字列が空 | |
| -n | 文字列が空でない |
数値比較と文字列比較で使用する演算子が異なるので注意しましょう。
#!/QOpenSys/pkgs/bin/bash VAR="abc defg" if [[ $VAR = "abcdefg" ]]; then echo "OK" else echo "NG" fi
条件式をダブル・ブラケットで囲むと、正規表現を使用することも可能になります。その場合、演算子は =~ を使用します(正規表現については、第9回「OSSツール Part-2」を参照)。
#!/QOpenSys/pkgs/bin/bash
VAR="351-002Q"
if [[ "$VAR" =~ ^[0-9]{3}-[0-9]{4}$ ]]; then
echo "OK"
else
echo "NG"
fi
上記は、変数の値が郵便番号として正しいかどうかを判断しています。
変数の値が日付の形式(簡易)として正しいかどうかを判断する場合は、
#!/QOpenSys/pkgs/bin/bash
date_str="2023-10-27"
if [[ "$date_str" =~ ^[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01])$ ]]; then
echo "$date_str は日付形式です。"
else
echo "$date_str は日付形式ではありません。"
fi
とします。上記正規表現は、うるう年チェックや存在しない日付(例えば 2025-02-30 など)のチェックはしないので注意しましょう。
制御構造(for)
リスト内の要素に対して繰り返し処理を行うには for 文を使います。例えば、配列の値を順次処理するような場合です。
for 変数 in リスト; do # 繰り返し処理 done
#!/QOpenSys/pkgs/bin/bash
array=("Blue" "Red" "Yellow")
for Color in "${array[@]}"; do
echo "選択された色は $Color です。"
done
Colorという変数は事前に値をセットしていませんが、上記の例では array の各要素を Color に代入しているため、変数として使用できます。
制御構造(while)
条件が真である間、繰り返し処理を行うには while 文を使います。
while [ 条件 ]; do # 繰り返し処理 done
ループを5回繰り返す場合は、以下のように記述します。
#!/QOpenSys/pkgs/bin/bash
count=1
while [ ${count} -le 5 ]; do
echo "Count: ${count}"
count=$((count + 1))
done
count=$((count + 1))
ここについては、解説が必要ですね。
シェルは変数を基本的に文字列として扱うため、算術式を実行するには適切な書き方が必要です。算術式を二重括弧「(())」で囲むことで、シェルに対して計算式として評価するよう明示的に指示できます。
二重括弧内では、変数を参照する際に $ を付ける必要はありません。例えば、(( a + b )) のように書くだけで、変数 a と b の値が自動的に参照されます。
また、計算結果を変数に代入する場合は、二重括弧の前に $ を付けます。例えば、result=$(( a + b )) のように書くと、a + b の計算結果が result に代入されます。
つまり、
count=$((count + 1))
の意味は、まず、
$((count + 1))
で、count 変数に 1 を足し(二重括弧で計算式として評価させる)、計算結果を二重括弧の先頭に $ を付けて戻し、
count=$((count + 1))
で、それを変数 count に代入するという意味になります。左辺の変数名にも $ をつけません。$ をつけるのは変数の値を参照する場合のみです。間違えやすいので注意しましょう。
引数
シェルスクリプトでは、引数を渡してそれをスクリプト内部で参照することができます。内部で参照するには、以下の特別な変数(代表的なもの)を使用します。
| 変数名 | 変数の内容 |
|---|---|
| $1 | 1番目の引数 |
| $2 | 2番目の引数 |
| $x | x番目の引数 |
| $# | 引数の個数 |
| $@ | 全ての引数を個別の文字列として参照 |
上記の変数を使用したシェル・スクリプトのサンプルは以下の通りです。
#!/QOpenSys/pkgs/bin/bash echo "引数の個数:$#" echo "最初の引数:$1" echo "2番目の引数:$2" echo "3番目の引数:$3" for var in $@; do echo $var done
上記シェルスクリプトを file01.sh として保存したとして、3つの引数を渡して実行すると以下のように出力されます。
-bash-5.1$ ./file01.sh aa bb cc 引数の個数:3 最初の引数:aa 2番目の引数:bb 3番目の引数:cc aa bb cc
コメント
シェルスクリプト内にコメントを追記したい場合は、行の先頭に # を指定します。他のプログラミング言語同様、適切なコメントを記述するようにしましょう。
#!/QOpenSys/pkgs/bin/bash : # この行はコメントです。 :
シェルスクリプトはプログラミング言語の一つですが、日常的な操作を自動化する簡単な作業から始めると、とても理解しやすいものだと思います。これから、いくつか簡単なサンプルを紹介しますので、皆さんもきっと実践してみたくなるものが見つかるでしょう。
3. 日常業務を効率化
シェルスクリプトの基本的な書き方は理解できたと思いますので、続けて、日常業務を想定した簡単なシェルスクリプトを作ってみましょう。ここでは、まず以下を行うシェルスクリプトを取り上げます。
- syslog.log ファイルの監視
- Apache ログファイルを定期的にバックアップ
syslog.logファイルの監視
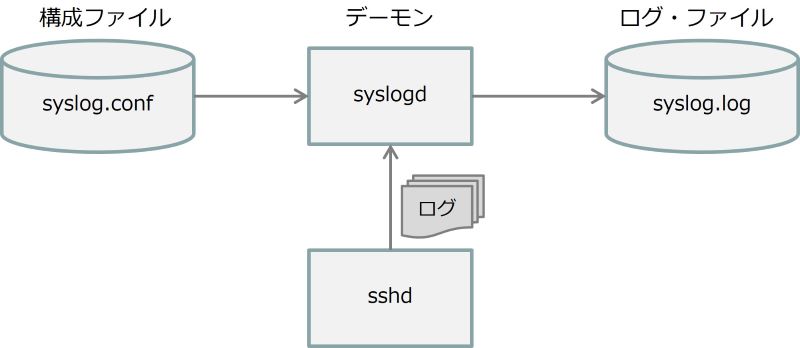
第7回の記事の通りに、IBM i で syslogd の構成および開始が行われていると、 /var/log/syslog.log ファイルにssh接続のログが記録されているはずです。このログを定期的に監視することにより、不正アクセス等を早期に検知可能です。
syslogdは、PASE環境にて様々なログを収集するためのプログラム(デーモン)でしたね。詳細は、第7回「クライアント認証とsyslog」を参照してください。ここでは、ssh接続時のログを収集するプログラムという位置づけで解説しています。
syslog.log に記録されるログの以下の文字列は、特に気をつけるべきものです。
| 文字列 | 意味 |
|---|---|
| Failed password for invalid user | 存在しないユーザー名でのログイン試行 |
| Failed password for xxxxxx | ユーザー xxxxxx のパスワード認証失敗 |
| Connection closed by authenticating user | 存在しているユーザーの認証後に接続が切断(不正なアクセス等) |
| Connection closed by invalid user | 存在しないユーザー名での接続試行後の切断 |
ファイルの文字列を検索するには、egrepが便利でしたね(第9回「OSSツール Part-2」参照)。例えば、不正アクセス後のログを参照するには、以下のように記述します。
Feb 23 21:00:30 SPIKE auth|security:info sshd[34987]: Connection closed by invalid user abcdefg 172.23.1.148 port 49829 [preauth]
Feb 23 21:10:56 SPIKE auth|security:info sshd[34993]: Connection closed by authenticating user ogawa 172.23.1.148 port 50079 [preauth]
Feb 23 21:16:35 SPIKE auth|security:info sshd[34996]: Connection closed by invalid user abcdefg 172.23.1.148 port 50329 [preauth]
上記によると、存在しているユーザー ogawa の接続が1回、存在しないユーザー abcdefg の接続試行が2回発生していることがわかります。
では、ogawa ユーザーの接続が切断されている理由を確認してみましょう。上記ログの前半に「sshd[34993]」という文字列が見えますが、これは、
- sshdが出力したプロセス ID 34993 のログ
ということを示しています。Connection closed by は、そのプロセスの最後のメッセージなので、同じプロセス ID の前のログを見ると原因がわかる可能性が高いはずです。では、同じプロセスを持つログのみを egrep で抽出してみましょう。
Feb 23 21:10:54 SPIKE auth|security:info sshd[34993]: Failed password for ogawa from 172.23.1.148 port 50079 ssh2
Feb 23 21:10:56 SPIKE auth|security:info sshd[34993]: Connection closed by authenticating user ogawa 172.23.1.148 port 50079 [preauth]-bash-5.1$ egrep
21:10:54のログで Failed password for とあるので、既存のユーザー ogawa のパスワード認証で失敗(パスワードを間違えている可能性がある)ということがわかります。このログがたくさん出ている場合は、「不正アクセスの可能性がある」と判断ができますね。
正規表現において、ブラケット [ ] は文字クラス(文字の集合)を表すメタ文字であり、特定の状況ではバックスラッシュ \ でエスケープする必要があります。そのため、正しいマッチングを行うためには注意が必要です。
しかし、毎回、egrepを手動で実行するのは手間がかかるため、シェルスクリプトにしておくと便利です。スクリプト化することで、誰でも簡単に実行でき、コマンドの入力ミスも防げます。
checklog.sh
egrep ‘Connection closed by’ /var/log/syslog.log
checkdetail.sh
egrep “sshd\[$1\]” /var/log/syslog.log
まず checklog.sh にてログを確認し、表示されたログから深堀りしたいプロセス ID を checkdetail.sh の引数に指定します。上記を実行した例です。
Feb 23 21:00:30 SPIKE auth|security:info sshd[34987]: Connection closed by invalid user abcdefg 172.23.1.148 port 49829 [preauth]
Feb 23 21:10:56 SPIKE auth|security:info sshd[34993]: Connection closed by authenticating user ogawa 172.23.1.148 port 50079 [preauth]
Feb 23 21:16:35 SPIKE auth|security:info sshd[34996]: Connection closed by invalid user abcdefg 172.23.1.148 port 50329 [preauth]
-bash-5.1$ ./checkdetail.sh 34993
Feb 23 21:10:54 SPIKE auth|security:info sshd[34993]: Failed password for ogawa from 172.23.1.148 port 50079 ssh2
Feb 23 21:10:56 SPIKE auth|security:info sshd[34993]: Connection closed by authenticating user ogawa 172.23.1.148 port 50079 [preauth]
Apacheログファイルを定期的にバックアップ
IBM i で構成されたApacheのログファイルは、作成したWebサーバーに関連するディレクトリー内のlogsディレクトリーに記録されます。例えば、Webサーバー名が testsvr の場合、ログファイルのディレクトリーは /www/testsvr/logs です。
一般的なWebサーバーの構成では、アクセスログは7日間でローテーションされます(1 週間前のログから削除されます)。そのため、必要に応じて構成を変更するか、定期的にバックアップを取る必要があります。
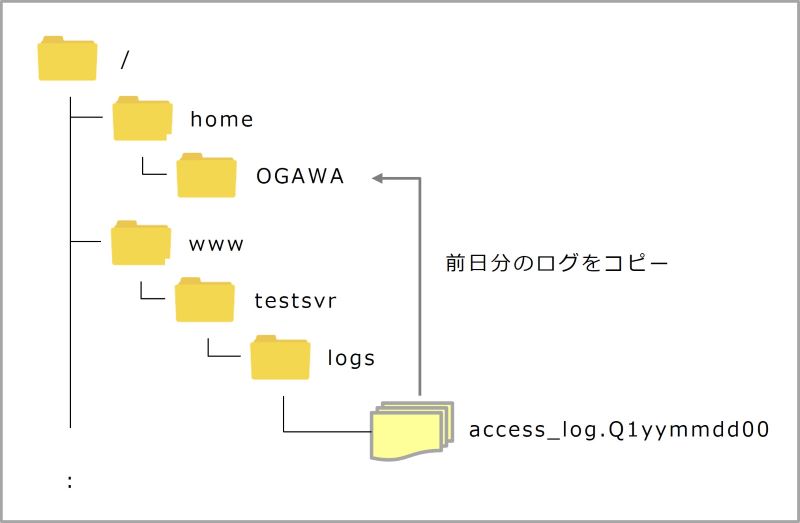
図のように、前日のログファイルを別のディレクトリーにコピーするシェルスクリプトを考えてみましょう。まず、ログファイルのどこを見れば、前日のものであるかを判断できるのでしょうか?
アクセスログファイルは、ファイル名の拡張子部分に日付情報が含まれています。
/www/testsvr/logs/access_log.Q125022200
上記ログファイルの例では、拡張子部分の3桁目から 8桁目までが yymmdd 形式で、2025年02月22日のログであることがわかります。つまり、昨日の日付を yymmdd 形式で取得して、拡張子の日付部分にその日付をセットすれば、それが昨日のログファイルと判断できますね。
では、前日の日付を yymmdd 形式で取得するにはどうすればよいのでしょうか。これは、以下の様に記述して取得できます。
YESTERDAY=$(date -d "yesterday" +"%y%m%d")
まず、$() の部分ですが、これは、括弧内のコマンドを実行して、その値を戻したい時に使用します。算術用の二重括弧と区別してください。
実行するコマンドは date を使用しています。-d に続いて “yesterday” を指定することで、前日の日付情報を戻します。直接実行すると、例えば、以下のような結果になります(2025/02/23 に実行した場合)。
-bash-5.1$ date -d "yesterday" Sat Feb 22 22:08:58 2025
次に +”%y%m%d” ですが、以下の2つに分解できます。
| 項目 | 意味 |
|---|---|
| + | 出力フォーマットの指定 |
| “%y%m%d” | yymmdd 形式 |
出力フォーマットも指定して直接実行すると、以下の結果が表示されます。
-bash-5.1$ date -d "yesterday" +"%y%m%d" 250222
上記を取得して、変数 YESTERDAY にセットし、コピー対象のファイル名を作成してコピーするように記述したシェルスクリプトが以下です。
#!/QOpenSys/pkgs/bin/bash
YESTERDAY=$(date -d "yesterday" +"%y%m%d")
LogFileName="/www/testsvr/logs/access_log.Q1${YESTERDAY}00"
cp "$LogFileName" /home/OGAWA/
このシェルスクリプトを毎日1回実行すれば、前日のログファイルが /home/OGAWA ディレクトリにコピー(退避)できますね。
4. データ転送
続いて、データ転送を行うシェルスクリプトのサンプルを考えてみましょう。
第6回「ファイル転送」で、安全にファイル転送を行う手段として「sftp」と「scp」を解説しました。そこでお話したのは、sftpは対話モードで、scpはバッチモードでそれぞれ転送可能であるということです。
scpがバッチモードということは、シェルスクリプトと相性が良いというのは皆さんお分かりいただけますよね。転送するファイルや、転送サーバーなどを引数で受取り、状況に応じて送信するか受信するかを判断したり、どのサーバーと送受信するかの処理を分岐するなど、かなり自由に設計できると思います。
しかし、第10回「OSSツール Part-3」で紹介した chroot の構成(internal-sftp)を行うと、そのサーバーへのファイル転送は、基本的にsftpしか許可されなくなります。つまり、scpでのファイル転送は実行できないのです。
一方で、セキュリティー重視の構成はchrootが推奨されますから、そのような環境でデータの送受信をバッチモードで行いたい場合はどうすればよいのでしょうか?
実は、sftpは、実行するsftpコマンド(put、get、bye など)が書かれたテキスト・ファイルを読み込んで、バッチモードで実行することも可能です。バッチモードを使用するには「-b」を指定してsftpを実行します。
sftp -b < script.sftp hostName
| 項目 | 意味 | 備考 |
|---|---|---|
| sftp | sftpコマンド | |
| -b | バッチモードで実行 | |
| < | リダイレクト | 右辺のファイルを sftp に渡す |
| script.sftp | sftpにバッチモードで実行させるコマンドのリスト | |
| hostName | ~/.ssh/config内で定義したホスト名 | 公開鍵認証で構成 |
hostNameを構成する ~/.ssh/configファイルに関しては、第7回「クライアント認証とsyslog」を参照してください。
別のサーバーにファイル転送
では、sftpのバッチモードで、別のサーバーにIBM i からファイルを転送してみましょう。今回は以下の3つを前提に進めていきます。必要に応じて過去記事を参照してください。
- 接続先のIBM i は、chroot設定済(第10回「OSSツール Part-3」)
- 接続ユーザーは ogawa2(第7回「クライアント認証とsyslog」)
- クライアント認証は公開鍵認証で構成済(第7回「クライアント認証とsyslog」)
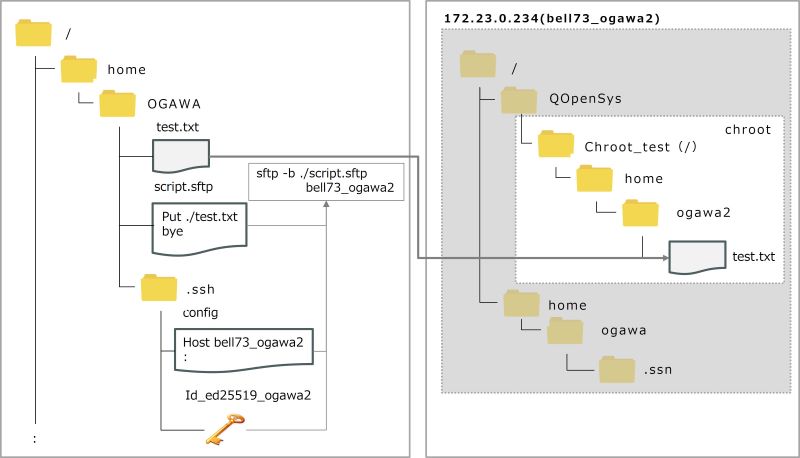
script.sftpファイルには、以下を記述します。
put ./test.txt bye
また、~/.ssh/configには、以下の設定を登録済です。
Host bell73_ogawa2 HostName 172.23.0.234 User ogawa2 Port 22 IdentityFile ~/.ssh/id_ed25519_ogawa2
では、上記条件で、sftpを実行してみましょう。
-bash-5.1$ sftp -b ./script.sftp bell73_ogawa2 sftp> put ./test.txt sftp> bye -bash-5.1$
転送先のIBM i で、ファイルが転送されていることを確認しましょう。
-bash-5.1$ pwd /QOpenSys/chroot_test/home/ogawa2 -bash-5.1$ ls -l total 8 -rwxr-xr-x 1 ogawa2 0 71 Feb 24 12:54 test.txt -bash-5.1$
転送ファイルを引数で
では、転送ファイル名を引数で受け取り、そのファイルをsftpのバッチモードで別のサーバーに転送するシェルスクリプトを考えてみましょう。
#!/QOpenSys/pkgs/bin/bash echo "put ./$1" > ./script.sftp echo "bye" >> ./script.sftp sftp -b ./script.sftp bell73_ogawa2
上記シェルスクリプトは、最初に引数の値を、文字リテラル "put ./" と連結し、echoを使用して ./script.sftp に書き込んでいます。「 > 」を使用しているので、同名のファイルがあれば内容を上書きします。
続いて文字列 "bye" を同じファイルに書き込みます。使用しているのは「 >> 」なので、先ほど追記した行の次に追記されます(リダイレクトの > および >> については、第3回「シェルと基本コマンド」を参照してください)。
その次のsftpは先ほど解説したバッチモードでの実行なので、お分かりですね。
では、上記ファイルを filecopy.sh という名前で保存し、実行属性を付けて実行してみましょう。
-bash-5.1$ ./filecopy.sh test2.sh sftp> put ./test2.sh sftp> bye -bash-5.1$
正しく実行されたようです。では、転送先のサーバーで確認してみましょう。
/QOpenSys/chroot_test/home/ogawa2 -bash-5.1$ ls -l total 16 -rwxr-xr-x 1 ogawa2 0 71 Feb 24 12:54 test.sh -rwxr--r-- 1 ogawa2 0 106 Feb 24 13:18 test2.sh -bash-5.1$
引数で渡した test2.sh ファイルがコピーされていますね。
5. ジョブ・スケジューリング
さて、syslog.logファイルの監視やApacheログファイルのバックアップの実行、ファイル転送を実施するシェルスクリプトを紹介してきましたが、実運用ではこれらを手動で実行することはなく、スケジュール登録して自動実行するのが一般的です。
IBM i にも当然、ジョブ・スケジュールの機能が備わっているので、これを利用する方法を考えてみます。
IBM i のジョブ・スケジュール機能では、実行するジョブをジョブ・スケジュール項目として登録し、指定した日時にシステムが自動でそのジョブを実行します。
ジョブをスケジュール項目として登録するには、ADDJOBSCDE コマンドを使用します。例えば、前述のApacheのログファイルのバックアップ(logcopy.sh という名前で保存し、実行属性を付与していると仮定)を毎日午前1時に実行するように登録するには、以下のコマンドを使用します。
ADDJOBSCDE
JOB(LOGCOPY)
CMD(STRQSH CMD('/home/OGAWA/logcopy.sh'))
FRQ(*WEEKLY)
SCDDATE(*NONE)
SCDDAY(*ALL)
SCDTIME(010000)
USER(OGAWA)
上記は、ネイティブ環境(5250接続)でのコマンド実行ですが、sshセッションで登録するには以下を実行します。
CPC1238: ジョブ・スケジュール項目LOGCOPYの番号000016が追加された。
スケジュール登録できたかどうかを WRKJOBSCDE コマンドを実行して確認してみましょう。
bash-5.1$ system 'wrkjobscde'
ジョブ・スケジュール項目の処理 ページ 1
5770SS1 V7R4M0 190621 SPIKE74 25/02/23 22:31:56 JST
項目 --スケジュール--- 回復 ---ニ゙ュボ 待ち行列--- ヌiニ゙ャーモ
ジョブ 番号 STS 日付 時刻 Fハト 処置 待ち行列 [bボ[メー マーナ゙ー テキスト
CPYF 000006 HLD *MON 01:00:00 *WEEKLY *SBMRLS *JOBD TATHA
LOGCOPY 000016 SCD *ALL 01:00:00 *WEEKLY *SBMRLS *JOBD OGAWA
* * * * * リ ス ト の 終 わ り * * * * *
登録が確認できれば、毎日午前 1 時に /home/OGAWA/logcopy.sh が自動的に実行されます。
cron
Linux / AIX 環境には、システム・スケジューラの cron があります。IBM i 用には、OSSの cronie という名前でバイナリが用意されているので、以下コマンドを実行して導入されているかを確認し、未導入であればインストールしておきましょう。
bash-5.1$ yum list installed | grep cronie -bash-5.1$
インストールにはもちろん、yum を使用します。
-bash-5.1$ yum install cronie インストール処理の設定をしています 依存性の解決をしています --> トランザクションの確認を実行しています。 ---> Package cronie.ppc64 0:1.5.5-4 will be インストール --> 依存性解決を終了しました。 依存性を解決しました ============================================================================================== パッケージ アーキテクチャ バージョン リポジトリー 容量 ============================================================================================== インストールしています: cronie ppc64 1.5.5-4 ibmi-base 357 k トランザクションの要約 ============================================================================================== インストール 1 Package 総ダウンロード容量: 357 k インストール済み容量: 357 k これでいいですか? [y/N]y パッケージをダウンロードしています: cronie-1.5.5-4.ibmi7.2.ppc64.rpm | 357 kB 00:00:01 トランザクションのチェックを実行してします。 トランザクションのテストを実行しています トランザクションのテストを成功しました トランザクションを実行しています インストールしています : cronie-1.5.5-4.ppc64 1/1 インストール: cronie.ppc64 0:1.5.5-4 完了しました! -bash-5.1$
インストールが完了したら、crondを実行しておきましょう。
-bash-5.1$ crond
上記コマンドにより、crondがQUSRWRKサブシステム内で実行されます。crondは、IBM i システムが再起動された場合は再度実行する必要がありますので注意してください。
-bash-5.1$ system 'wrkactjob sbs(qusrwrk)' | grep crond QP0ZSPWP QSECOFR 337550 QSECOFR BCI 2 50 .0 0 .0 PGM-crond THDW 1 10
cronの構成
スケジュール実行したいコマンドは、/QOpenSys/etc/crontab に記述します。cronie導入直後のファイルの内容は、以下のようになっているはずです。
SHELL=/QOpenSys/pkgs/bin/bash PATH=/QOpenSys/pkgs/bin:/QOpenSys/usr/sbin:/QOpenSys/usr/bin MAILTO=qsecofr # For details see man 4 crontabs # Example of job definition: # .---------------- minute (0 - 59) # | .------------- hour (0 - 23) # | | .---------- day of month (1 - 31) # | | | .------- month (1 - 12) OR jan,feb,mar,apr ... # | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat # | | | | | # * * * * * user-name command to be executed
最初の2行は、cronで実行するプロセスで使用するシェルと、PATH環境変数が設定されています。IBM i のOSS環境用に設定されているので、通常は変更しなくてもよいでしょう。
先頭が # の行はコメント行で、どのようにコマンドをスケジュールするかの書き方を説明しています。実際の登録内容を例に、どのように記述するのか少し詳しくみていきましょう。
* * * * * UserName /path/to/command
まず、最初の5つのアスタリスクは、左から順に「分 時 日 月 曜日」を表し、そのコマンドを実行したい頻度を指定します。
| 項目 | * | 指定パターン1 | 指定パターン2 |
|---|---|---|---|
| 分 | 毎分 | 0 - 59 | - |
| 時 | 毎時 | 0 - 23 | - |
| 日 | 毎日 | 1 - 31 | - |
| 月 | 毎月 | 1 - 12 | - |
| 曜日 | 毎分 | 0 - 6(0=日曜日) | sun、mon、tue、wed .... |
UserName は実行する IBM i のユーザー名、その後に実行するコマンドもしくはシェルスクリプト・ファイルを指定します。
上記の例では、「分 時 日 月 曜日」すべて * なので、/path/to/command が「毎分実行」されます。
ADDJOBSCDEコマンドを使用して指定したのと同様、毎日午前1時に /home/OGAWA/logcopy.sh を実行するには、vimを使用して以下を /QOpenSys/etc/crontab の最後に追記します。
0 1 * * * ogawa /home/OGAWA/logcopy.sh
ファイルの変更を保存すると、crondが自動的にファイルをリロードするので、crondの再起動等は必要ありません。
6. おわりに
今回は、IBM i のPASE環境で使用するシェルスクリプトについて取り上げました。基本的な書き方から、ログファイルの監視、バックアップ、データ転送を実行するスクリプトの記述方法、さらにスケジュール登録による自動実行の手順についても解説しました。ssh環境を活用することで、IBM i ネイティブの環境以外でも同様の処理が実現できることを実感していただけたかと思います。
今回は、シェルスクリプトの基本的な使い方を業務視点で解説しました。さらに、sshを経由すれば外部サーバー上に存在するシェルスクリプトを実行することも可能です。アイデア次第では、IBM i 同士に限らず、他のサーバーと連携して一つの業務や処理を協調して実行することもできるのです。今まで不可能だと諦めていた業務も、Linuxの視点からIBM i を見直すことで、新たな可能性が見いだせるかもしれません。
さて、早いもので、次回の記事がこの連載の最終回となります。最後はこれまでの内容を振り返りつつ、私なりの視点で「これからの IBM i」についてお話しさせていただければと思います。
それでは、最終回もどうぞお楽しみに!
参考文献
- Korinne's Ramblings.【IBM i Open Source Updates December 2020】
- ZDNET.【「Linux」で「cron」を使用してジョブをスケジュールするには】
- Gemini Advanced 2.0 flash
- ChatGPT 4o
- Claude 3.5 Sonnet
- Felo ai
- perplexity












連載第11回では、IBM i の Linux 環境をさらに活用するための重要な要素である「シェルスクリプト」に焦点を当て、その基本と応用について解説します。(編集部)