

2024年9月3日 チャーリー・グアリーノ
IBM ロチェスターで働くDb2 for IBM iのソフトウェア・エンジニアのライアン・モラー氏が、SQE(SQL Query Engine)、AQP(Adaptive Query Processing)、クエリー最適化を説明するとともに、IBM i に関するコミュニティーについて言及します。
| SQLクエリー・エンジン(SQE)と クラシック・クエリー・エンジン(CQE) |
クエリー最適化のための作業 |
| 適応QUERY処理(Adaptive Query Processing) | Db2 for iの特長 |
| コミュニティーとの交流で得られたもの | |
SQLクエリー・エンジン(SQE)とクラシック・クエリー・エンジン(CQE)
チャーリー・グアリーノ(以下、チャーリーと略します):
多くの開発者がSQLに関して思い浮かべるべきなのは、SQLクエリー・エンジン(SQL Query Engine:SQE。以降は「SQE」と記述)です。これは、プログラミングにおける重要な部分だと思います。
ライアンさん、SQEとはどのようなものですか? そして、SQEを気にするべき理由は何でしょうか?
ライアン・モラー(以下、ライアンと略します):
データベースは様々な部品で構成されています。
SQEは、SQLクエリー・エンジンという名称の通り、SQLクエリーの最適化を担っています。また、実行と統計処理も担っています。ですから、最適化されたクエリーの実行計画を司るオプティマイザーの強化に役立つデータベースの統計情報を大量に収集しています。これらがSQEの基盤となる3つの大きなコンポーネントです。
最終的な目標は、クエリー自体の大まかな表現を解釈し、それを実行して行を返すことです。もちろん、その処理の間には、複雑な統計学と、データサイエンスやテクノロジーなどが介在しています。
チャーリー:
つまり、何が起こっているのかをユーザーや開発者が気にしなくて済むように、非常に複雑な計算処理の大半が、IBM i によってユーザーや開発者とは無関係に行われているのですね。
ライアン:
その通りです。もちろん、IBM iが処理をしているのだから、気にする必要は無いとも言えます。ただし、クエリーのパフォーマンスを最大化し、オプティマイザーが最適化できる形式にするためには、動作の原理をある程度理解していただくことが望ましいです。
非常に複雑なトピックとなりますが、大規模で複雑なプロセスを調べる方法と、肝に銘じるべき事柄に関する入門ステップを取り上げるつもりです。
チャーリー:
最初に、歴史的な背景を説明しましょう。実は、SQEは当初からのエンジンではありません。名前が付いていたかどうか知りませんが、SQE以前にオリジナルのエンジンとして、クラシック・クエリー・エンジン(CQE:Classic Query Engine。以降は「CQE」と記述)がありました。CQEと呼ばれるようになったのは、SQEがリリースされてからです。
まず、今日においてもCQEについて知っている必要があるのでしょうか。そして、今でもCQEを使用しているものはあるのでしょうか。あるいは、全てがSQEを使用しているでしょうか。これらについて教えてください。
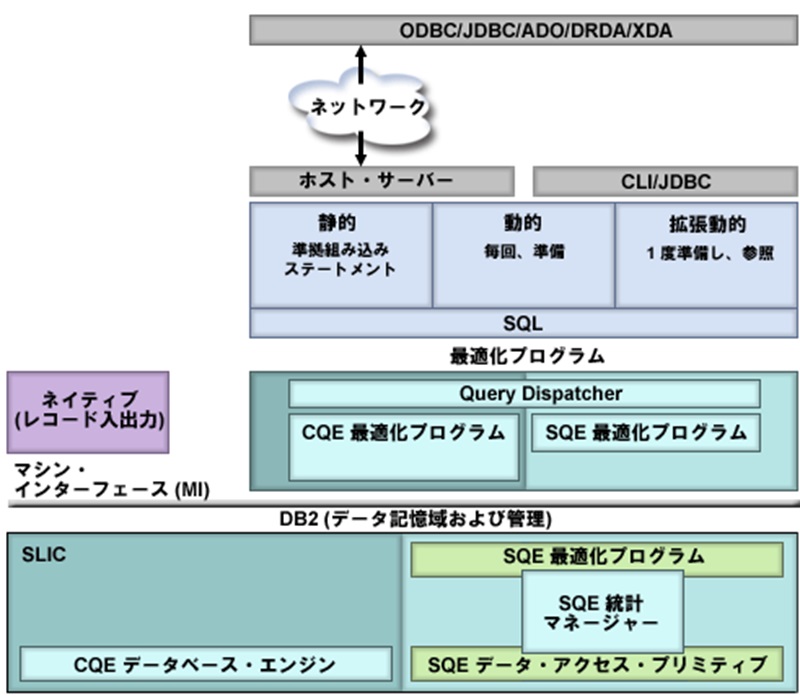
ライアン:
CQEは、SQLの登場以前にデータベースを動かしていたエンジンであり、IBMはそれにSQL機能を追加しました。そして、SQL 以外のクエリーを処理するクエリー・エンジンとして、現在もIBM iに存在しています。
CQEで実行されるものは限定的であり、私が知っている代表例は「読み取りトリガー」です。データベース・テーブルに「読み取りトリガー」がある場合、発行されたクエリーは、CQEを介して実行されます。これは非常に稀なケースで、99%以上のクエリーはSQEを介して実行されると思います。
IBMがSQEを作ったのは、エンジニアリングの観点からCQEの維持が困難だったからです。並行的にSQLの人気が上昇したことで、オプティマイザーをXPFからSLICに移動すればパフォーマンスを向上できることにIBMは気付きました。
XPFはアプリケーションが稼働するオペレーティングシステム・レイヤーのようなもので、SLICはカーネル(ライセンスの内部コード)です。つまり、オプティマイザーをカーネルで実行することで、パフォーマンス上のメリットが得られるわけです。ただし、このことは必ずしもクエリーの実行パフォーマンスの向上につながるわけではなく、最適化プロセスの向上につながることに注意してください。
多くの方が、クエリーを発行すると延々と続く状況に遭遇したことがあると思います。クエリーの最適化に数十分、数時間、あるいはそれ以上かかるケースも見られました。そして、これをCQEで実行した場合、パフォーマンスはさらに悪くなります。
Db2 for iのチームはオプティマイザー/エンジンを拡張する能力の維持に注力しており、CQEからSQEへの移行を決めた切実な理由でした。
チャーリー:
あなたは、例外があることと、例外の代表例として「読み取りトリガー」に言及されましたが、今後、読み取りトリガーをCQE以外の何かに変更する予定はあるのでしょうか? その場合、アプリケーション全体のパフォーマンス向上に役立ちますか? 例えば、読み取りトリガーを使用したくないと思う十分な理由になりますか?
ライアン:
答えは、状況によって異なります。
CQEは古いテクノロジーであるというだけです。CQEは非常にシンプルなので独自の利点があり、そのシンプルさが際立つこともたまにあります。逆に少し複雑になり過ぎることもありますが、CQEの使用を必ずしも危険信号と見なすわけではありません。
確かにこれは、使用しているアプリケーションがレガシー形式で記述されているか、レガシーツールを使用していることを意味しますが、また、新しい開発者に加わって作業してもらうために、SQEにアップグレードするべきか否かは、パフォーマンスの観点とは全く別の議論です。
SQLパフォーマンスの観点からは、それほど心配する必要はありませんが、可能であればSQEに移行することをお奨めします。しかし、繰り返しますが、少量のクエリーであり、データベース全体のごく一部です。ですから、CQEの使用量が著しく多い場合を除き、あまり心配する必要はありません。
チャーリー:
パフォーマンスに重大な問題がない限り、CQEに時間を費やすべきではなく、重大な問題がある場合に限り深く掘り下げる必要があるということですね。
ライアン:
そうです。 IBM® i Access Client Solutions (ACS) を介して利用できる プラン・キャッシュ・スナップショットを作成すると、実行されたクエリーの数をCQEとSQEで比較できます。CQEで実行されているクエリーの割合が10%程度の場合は、使用量が著しく多いと判断できます。特定のクエリーでパフォーマンスの問題がある場合は、確認してみる価値があるかもしれません。
チャーリー:
意図的にCQEから移行する方法はありますか? 例えばSQL経由で標準クエリーを実行している場合は、SQLにCQEに移動する特定の関数がない限り、そうはならないと思いますが。
ライアン:
以前はCQEに送られていたオープンクエリー・ファイル(OPNQRYF)でさえ、現在ではその大部分はSQEに送られます。また、SQLの使用に関して言えば、Query/400やOPNQRYFなどの古いインターフェースから、JDBCやODBCコネクタなどのより新しいツールに移行する場合、本質的にSQEに移行することになります。CQEからの移行というよりは、全体像から見て、テクノロジーを現代的かつ強力で新しいものに移行したほうが良いかもしれません。
クエリー最適化のための作業
チャーリー:
開発者の観点から、「最適化されたクエリー」とは何を意味するのでしょうか?
ライアン:
エンジニアリングの観点からは、最適化のプロセスまたは目標は、クエリーの実行に要する時間を最小限に抑えることです。クエリーを発行する場合、クエリーが複雑であればあるほど、実装可能な種類や特色が増えます。
例えば、2つのテーブルを含むクエリーがあり、それらを結合する場合、可能な順序は「テーブルAをテーブルBに結合」と「テーブルBをテーブルAに結合」の2つだけですが、3つ目、4つ目、5つ目のテーブルの追加や、インデックス作成、順序付け、グループ化といった様々な要素を考慮すると、状況は複雑になります。その影響で、比較的コンパクトですっきりしていて分かり易いクエリーが突然大きくなり、様々な実装について全ての可能性を検討する必要が生じます。
オプティマイザーは、優れたパフォーマンスを発揮するプランを見つけるためロジックが多数用意されています。パフォーマンスの最高の指標は、実行にどれくらい時間がかかるかという経過時間です。これを最小限に抑えるように努めています。
チャーリー:
クエリーの構造化方法も、実行方法に直接影響する可能性があると聞きました。Visual Explainは、あるクエリーと別のクエリーを識別し、両者のパフォーマンスの確認に役立ちますか?
ライアン:
Visual Explainは、基本的にはクエリーの図を描く優れたツールです。クエリーは、ノードと呼ばれる様々な部分で構成されています。
ノードの一例はテーブル・スキャンであり、テーブルを見て、1行目からデータを調べ始め、最後まで進みます。ノードには様々な種類(リスト、ソート済みリスト、ハッシュテーブルなど)の一時的なデータ構造があります。これらのノードは、すべてクエリーがどのようになるか図を描くために一緒に構築されます。オプティマイザーはクエリーが返す行数と所要時間を推測します。
Visual Explainの情報は多くの場合は推定値なので、完全に正確とは限りませんが気にする必要はありません。もちろん、可能な限り正確な見積もりを提供して、Visual Explainで公開できれば素晴らしいことですが、重要なのは相対的な比較だからです。
チャーリー:
開発者はあなたが今説明したレベルまで本当に知る必要があるのでしょうか? 開発者がこれらの事についてもっと知っていれば、より優れた開発者になれるでしょうか?
ライアン:
答えが「いいえ」であることを、この会話が証明しています。
平均的なIBM i利用企業に行って「データベース・エンジニアはいますか?」と尋ねたら、答えはほぼ間違いなく「いいえ」でしょう。なぜなら、IBM i は人々に代わって大変な作業の多くを処理しているからです。IBM iの価値提案の1つは自己保守性であり、保守にコストがかからないことです。だからこそ、IBM i では、システム管理者はパフォーマンスと物事がうまく機能していることを確認することだけに集中できるのです。したがって、一般的な開発者は最適化について詳しく知る必要はありません。
ただし、クエリーの最適化について学びたい場合は、パフォーマンス、可読性、保守性などの点でもっと良いクエリーを作成する方法を学ぶ必要があります。
RPGに埋め込まれたSQLを書いていて、うまく機能しているけれど更に掘り下げたいと考えている場合、Visual Explainは素晴らしいツールです。クエリーの実行速度を上げ、アプリケーションの応答性を高め、ユーザーを満足させられます。
適応QUERY処理(Adaptive Query Processing)
チャーリー:
あなたにとって非常に興味深い話題または議論するのが好きな話題の1つに、適応QUERY処理(Adaptive Query Processing:AQP。以降は「AQP」と記述)がありますよね。なぜ、AQPが重要なのかを教えてください。
ライアン:
クエリーの最初のステップは、クエリーを最適化して何らかの実行プランを作成することです。プランを実行すると、数値を計算して、ユーザーに返す行を構築します。行の構築は非常に複雑な操作であり、数ミリ秒で済む場合もあれば、実行内容によっては数時間かかる場合があります。また、クエリーが返す行数と所要時間は推定に基づいていることから、大規模なクエリーの中には、最初から正しく実行できないものもあります。
AQPは、オプティマイザーによる誤った判断や不適切な推定を修正するために開発されたものであり、クエリー実行の2秒後に起動するセカンダリ・スレッドです。
AQPの主な仕事は、クエリー・ツリー内の各ノードの行数と時間を調べることであり、起動するとAGPは実行中のクエリーを調べ始めます。
そして、期待している結果とAQPの調査によって見える結果が類似している場合は、クエリーが返す行数の見積もりが適切で最適化プロセスがうまく機能していることを意味します。
しかし、行数が10倍程度違っているなど、両者の結果が異なるような場合は、最適化プロセスがうまく機能したかどうかが疑わしくなってきます。最適化プロセスに影響を及ぼす大きな要因の1つが、結合順序と呼ばれるものです。クエリーに2つのテーブルがある場合、「テーブルAをテーブルBに結合」と「テーブルBをテーブルAに結合」の2つの結合順序があることになります。この結合順序は、データベースの最適化において非常に重要なトピックです。
結合順序はオプティマイザーの仕事ですが、間違えることもあります。また、VARCHAR(可変長文字)列の部分列の結合のような非常に奇妙な結合句が与えられた場合は、オプティマイザーの問題とは言い切れないため、非常に厄介です。
統計処理を担うSQEは、異なる全ての列とその列に含まれる値に関する情報を収集します。例えば州の列がある場合、ミネソタ、イリノイ、ニューヨークに割り当てられる値が大体いくつになるかを調べます。ただし、数が多すぎるため、全ての値を見ることは困難です。また、注意するべき点として、SQEは値全体を見るのであって、値の一部を見るのではない、ということがあります。つまり、文字列の部分列を取得して結合に使用する場合、テーブルの結合にSQEを使用してもほぼ失敗します。
結合述語が非常に奇妙とAQPが判断した場合、クエリーを強制終了させた上で、テーブルの結合順序を変更して、クエリーを再開します。この場合、作業が90%完了していたとしても、2つの理由からAQPはクエリーをいったん終了させて再開します。
理由の1つは、実際のところ、進捗状況が分からないからです。全てが見積もりに基づいていて、しかも、その見積もりがどの程度優れているかが分かりません。そのため、90%完了しているのか、10%完了しているのかは分かりません。分かるのは、何か悪いことが起きているということだけなので、その状況から脱する必要があります。 もう1つは、再利用です。クエリーを最適化または実行した際に、そのクエリーはプラン・キャッシュと呼ばれる場所に保存されます。
プラン・キャッシュは一度だけ最適化すれば良く、同じクエリーを何回も実行する場合には、クエリーを実行するために作成したプランが再利用できます。ただし、パフォーマンスの低いクエリーが存在した場合は、そのクエリーを終了させないと何回も再利用し続けることになるため、非常に問題です。AQPはプラン・キャッシュ内のプランも更新するので、将来実行するクエリーは以前のものよりも高速になります。
そして、各クエリーに対してこれを複数回実行します。また、オプティマイザーには、適応型クエリー処理やSMP (対称マルチプロセッシング)といった新しい機能を常に追加しています。
現在、SMPを支援するためAQPを使用しています。SMPの使用をシステムで管理するのは困難でしたが、AQPは自動的にクエリーを確認して、SMPのメリットがあるかどうかを実行時間に基づいて判断し現SMPの使用を自動的に処理しています。これらの作業は、ユーザーの作業を大幅に軽減するためにIBM i が内側で代わりに行いますが、このすべての本質を理解すれば、本当に成功を収める開発者になれると思います。
チャーリー:
AQPの場合、先ほどの例示されたようなミネソタ、ニューヨーク、イリノイといった州名を選んでも違いはありません。データベースは、例えば異なる州のセットがあったり、ある州が他の州よりも多かったりすると、クエリー自体の実行方法やAQPが異なるプランを作成する方法に影響するのでしょうか? あるいは、データに依存するのでしょうか? それとも実際にAQPの動作に影響を与えるのはクエリーの設計だけなのでしょうか?
ライアン:
それは、返されるデータによります。
AQPとオプティマイザー全般の難しい点は、クエリーを発行すると、入力したリテラル(プログラム中で参照できる自己定義定数)を取り除くことです。クエリーに「=5」や「=Wisconsin」、「=Minnesota」などがある場合、通常、オプティマイザーはそれらの正確な値を認識しません。つまり、「=?」は認識しますが「=MN」は認識しません。このようなユーザー・プログラムによって定義されるデータ項目のことをホスト変数と呼びます。
よくあることとして、あるホスト変数のセットに対して非常に良く機能するプランが存在します。例えば、ニューヨークの各郡に住んでいる住民の数を調べているとします。ここで、その州のフィルターをミネソタに変更すると、全く別のデータセットになりますよね? 同じテーブルで、クエリーもほぼ同じかもしれませんが、基礎となるデータは大きく異なる場合があり、そのプランが実際には最適ではない可能性があります。
何年も前から、クエリーを再実行する際にホスト変数を検査できるチェック機能がありましたが、多くの場合、デフォルトで無効にされています。これで全く問題はありませんが、AQPはそのチェック機能を役立てるためにも存在します。
最初は1セットのホスト変数で実行したかもしれませんが、その後クエリーの処理を続けると、最適な方法で実行されていない可能性のある別のホスト変数で実行されることがあります。そのような場合に、AQPが介入して、「このクエリーを変更しましょう」と指示できるのです。また、AQPはクエリー構造にも基づいているので、データと構造は非常に密接に関係しています。満足のいくパフォーマンスを出すには両方が一貫した状態にあることが必要です。
Db2 for iの特長
チャーリー:
Db2 for IBM iが特別なのは、稼働しているハードウェアに合わせて最適化され、精緻に調整されているからだと思います。例えば、ある時点で使用されているディスクの種類は、クエリーのプランニングなどに直接影響するでしょう。Db2 for IBM iが特別である理由と、ハードウェアやOS、またはその両方向けに最適化されていると言われる理由を教えてください。
ライアン:
まず、OSの観点からお話ししましょう。
非常に特徴的なこととして、Db2 for iはオペレーティングシステムに統合されており、そのようなデータベース・ソリューションは多くありません。統合には多くの利点があり、最適化プロセスをカーネルに移行したことは、パフォーマンス上の大きなメリットです。
また、オペレーティングシステムの他の機能と非常に緊密に連携できます。例えば、メモリーにデータを保存する場合は、メモリーの使用を管理するコンポーネントに、このデータは実行中の非常に重要な高優先度プロセスであることを伝えられるので、当該データをディスクに出したり、メモリーからページアウトしたり、スワップファイルに入れるようなことは起きません。
他のプラットフォームでは、それをある程度制御する機能はありますが、IBM i程きめ細かく強力ではありません。また、最適化を実行すると、内蔵ストレージが実際はSSDかどうかを確認できます。もちろん、SSDは様々な状況でハードディスクよりも遥かに優れたパフォーマンスを発揮しますが、順次読み取りの観点ではハードディスクでも大きな問題はありません。つまり、アドレス1からアドレス10,000まで読み取るだけであれば、アドレス1、10,000、200と進むよりもずっと速くなります。
結果として、クエリーのI/O特性の理解が可能で、I/O特性に基づいて計画を立て、特定のクエリーに対して、どのようなソリューションやクエリー・ツリー構造が最適であるかを把握できます。また、内蔵ストレージの応答時間、データ取得に何ミリ秒を要したかを確認できます。そして、内蔵ストレージが遅いことが判明した場合は、その前提を計算に組み込むことが可能です。
また、IBM Powerという限定的なハードウェアセットで実行されるが故のハードウェア結合もあります。他のデータベースは、様々なハードウェアで実行できるが故に、実行可能なプロセッサーやメモリーなどの種類が膨大となる製品です。IBM iの場合、実行およびサポートできるプロセッサーの種類は1つまたは2つなので、それらのプロセッサーに合わせて最適化できます。
例えば、オプティマイザー内のデータ構造を最適化して、CPUのキャッシュ・ラインの幅を活用できます。IBM i はハードウェアとソフトウェアを非常にきめ細かく制御しており、最適化プロセスと実行時の両方で、非常に優れた利点をパフォーマンスにもたらします。
コミュニティーとの交流で得られたもの
チャーリー:
非常に簡潔で有益な回答ですね。ところで、本当にSQEに興味がある人は、多くの情報をどこで得られますか?
ライアン:
まずは、ユーザーグループや、イベントに参加してみることをお勧めします。IBMの社員と話すだけでなく、プラットフォームやデータベースについて基本的な理解を深めることで、オンライン上に回答が存在しないと思っていた質問にも答えられるようになると思います(編集部注)。
実際には、オンラインに各種のPDFがアップロードされており、最適化について全て説明されています。
「データベース・パフォーマンスおよびQuery最適化」というガイドでは、最適化プロセスの概要、オプティマイザーがどのように機能するか、Visual Explainとツールの様々な部分について概要が説明されています。また、インデックス戦略に関するRedbookがいくつかあり、データベース・インデックス戦略などに関して、価値のある情報が含まれています。オンラインのドキュメントを詳しく調べたり、ツールを実際に操作したりしてみるだけでも、非常に役立つことがあります。
チャーリー:
ところで、あなたは各地で講演をされ、イベントを数回経験し、ユーザーグループにも参加していますが、講演者として良い経験になったことはありますか?
ライアン:
私達の製品を使用している人々との会話が、すべてを価値あるものにしてくれます。講演後に誰かが私のところに来て、「すごくよかった。でも、パフォーマンスの問題で、プレゼンテーションでは答えられなかった別の質問があるんだけど、もっと詳しく教えてほしい」と言ってくれる時に、本当にやりがいを感じます。
コミュニティーとの交流がなかったら、IBM iに取り組むことにこれほど興奮することはなかったでしょう。そして、コミュニティーとの交流はIBMにとっても役に立ちます。共生関係ですよね? 私達は常にコミュニティーから素晴らしいアイデアを得ています。そして、これらのアイデアを直接聞いたり、問題や苦情や懸念を聞いたりすることで、私達が進むべき方向を導き出すことができます。これは、私達講演者にとっても、すべての参加者にとっても、本当に素晴らしい経験だと思います。
チャーリー:
共生関係という観点で、イベントに参加した多くの方々から、開発部門にいる人々にコンタクトできるという話を聞きました。率直に言って、あなたのような人々にそのようなアクセスを提供するプラットフォームを他にあまり知りません。これはIBMが提供してくれる非常に大きな価値であり、本当に素晴らしいことです。
ライアン:
IBMが36年間築いてきたコミュニティーとのやりとりと、共生関係がなければ、IBM iはそれほど優れた製品ではなかったと思います。
本記事は、TechChannelの許可を得て「Db2 for i, Under the Covers」(2024年9月3日公開)を翻訳し、日本の読者にとって分かりやすくするために一部を更新しています。最新の技術コンテンツを英語でご覧になりたい方は、techchannel.com をご覧ください。
(編集部注)ここでの発言は米国におけるコミュニティーを念頭に行われていますが、日本においても同様のコミュニティー活動がおこなわれています。詳しくはiWorldの記事「IBM i 若手エンジニアのためのコミュニティー」発足のお知らせ をご参照ください。また、iWorld会員限定にはなりますが、Q&AフォーラムもIBM iに関する知識吸収の場としてご活用いただけます。是非会員登録して使ってみてください。











日本でIBM i でSQLを利用するケースがあまり多くないのは何故でしょうか?
「だってAS/400のSQLは遅いんじゃない?」というお声を時々お聞きしますが、これはもう昔の話! 現在のDb2 for i とSQLはその使いやすさはそのままに、SQLインターフェースでもDDSアクセス以上のスピードを発揮します。
このDb2 for iの内側(内部構造)の概要を知ることは、IBM iの「高速性」「使い易さ」の秘密の本質を理解する上で意味があります。今回は、最新機能や生まれ変わったクエリー・エンジンの歴史的経緯も織り交ぜながら、Db2 for iがユーザーに代わって行っている複雑で大量の仕事について、対談記事の抄訳で紹介します。(編集部)