ニューラルネットワーク
前回ご説明したように、ディープラーニングは脳の神経細胞をモデルとして、ある神経細胞から次の神経細胞に情報(刺激)が伝達される様子をシミュレートすることで、これを人工知能に応用しようというものです。このモデルをニューラルネットワークと呼びますが、その基本的な考え方は、図1に示すようにごく単純なものです。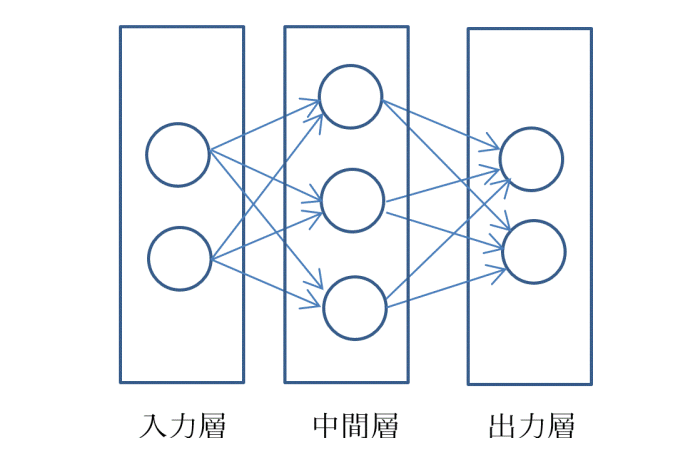 図1.単純なニューラルネットワークの例
丸印はノードと呼ばれ、神経細胞を表しています。またノードから次の層のノードに向かう矢印は刺激つまり情報の伝達を表しています。実際に使用するモデルは、各層のノードの数が数百から数千ともっと多く、中間層と書かれた部分も十層から数百層以上連なる複雑なモデルになりますが、この基本形を押さえておけばこの後の説明は十分ご理解いただけるでしょう。
図1.単純なニューラルネットワークの例
丸印はノードと呼ばれ、神経細胞を表しています。またノードから次の層のノードに向かう矢印は刺激つまり情報の伝達を表しています。実際に使用するモデルは、各層のノードの数が数百から数千ともっと多く、中間層と書かれた部分も十層から数百層以上連なる複雑なモデルになりますが、この基本形を押さえておけばこの後の説明は十分ご理解いただけるでしょう。
ディープラーニングのモデルとその実装
ディープラーニングではニューラルネットワークモデルを使って、情報の伝わり方をシミュレーションしますが、そのためにはノードに伝えられた入力信号を元に、次のノードへの出力信号の大きさを決定する必要があり、その作業をコンピューターで処理できるように数式の形で表したモデルを作成します。図2はその様子を模式的に表したものです。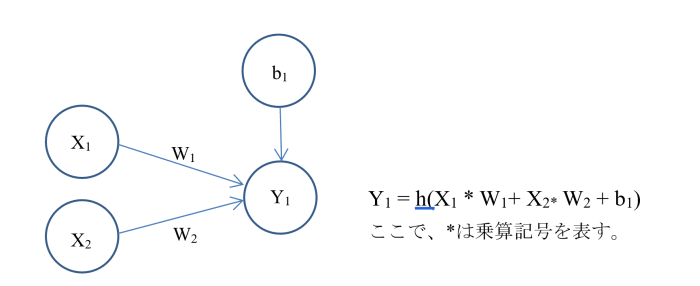 図2.入力信号を元にした出力信号の数値化
図2において、X1、X2はノードへの入力信号、Y1は次のノードに対する出力信号を表します。W1、W2はそれぞれ入力信号X1、X2に対する重み付けの値です。b1はバイアス値と呼ばれるもので、入力信号の総和を調整する役割を果たします。h(x)は活性化関数と呼ばれ、xの値に応じてどのような出力信号を出すかを決める関数です。たとえば、xの値が0以下であれば0を、xの値が0より大きければ1を出力するような関数(ステップ関数)や、xの値が0以下であれば0を、xの値が0より大きければxの値をそのまま出力するような関数(ReLU関数)などが使われます。
図2では入力信号がX1とX2の2つ、出力信号がY1の1つしかないので計算式はそれほど複雑ではありませんが、一般的にはもっと多くの入力信号、出力信号があるので、Y = ( Y1, Y2, … , Ym)、X = (X1, X2, … ,Xn)、B = (b1, b2, … ,bm)のように入力信号、出力信号、バイアス値をベクトルで表し、
図2.入力信号を元にした出力信号の数値化
図2において、X1、X2はノードへの入力信号、Y1は次のノードに対する出力信号を表します。W1、W2はそれぞれ入力信号X1、X2に対する重み付けの値です。b1はバイアス値と呼ばれるもので、入力信号の総和を調整する役割を果たします。h(x)は活性化関数と呼ばれ、xの値に応じてどのような出力信号を出すかを決める関数です。たとえば、xの値が0以下であれば0を、xの値が0より大きければ1を出力するような関数(ステップ関数)や、xの値が0以下であれば0を、xの値が0より大きければxの値をそのまま出力するような関数(ReLU関数)などが使われます。
図2では入力信号がX1とX2の2つ、出力信号がY1の1つしかないので計算式はそれほど複雑ではありませんが、一般的にはもっと多くの入力信号、出力信号があるので、Y = ( Y1, Y2, … , Ym)、X = (X1, X2, … ,Xn)、B = (b1, b2, … ,bm)のように入力信号、出力信号、バイアス値をベクトルで表し、
Y = h(XW + B)
ここで、Wは入力信号に対応する係数を要素に持つn行m列の行列
のように、行列を使った計算式を使って出力信号の値を算出します。
これで1つの層からの出力信号が求まり、それを次の層の入力信号として同様の計算を数珠つなぎに行ってゆくことで最終的な出力信号(結果)が求まることになります。つまり、ディープラーニングによる推論は、図3のように巨大な行列の計算をニューラルネットワークの層の数だけ繰り返し行う計算業務と見ることができます。
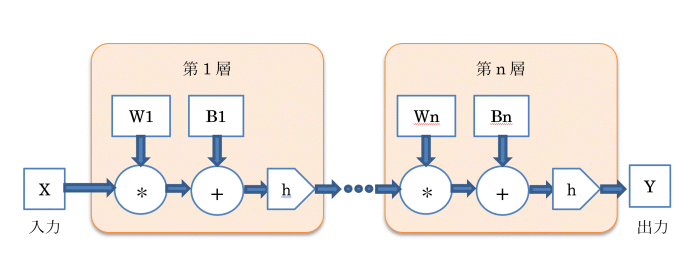 図3.計算処理から見たディープラーニングの概念モデル
また、訓練データを読み込み、できるだけ高い正解率を生み出すように図3のW1~Wn、B1~Bnを少しずつ変化させながら最適な値を決定する作業が、ディープラーニングにおける学習に相当しますが、これは推論を実行する場合よりもはるかに多くの行列計算を必要とします。
以上のことから、ディープラーニングにおける推論や学習は、大規模な行列計算を伴う処理プロセスであり、高い計算処理能力を求められることがお分かりいただけるでしょう。
図3.計算処理から見たディープラーニングの概念モデル
また、訓練データを読み込み、できるだけ高い正解率を生み出すように図3のW1~Wn、B1~Bnを少しずつ変化させながら最適な値を決定する作業が、ディープラーニングにおける学習に相当しますが、これは推論を実行する場合よりもはるかに多くの行列計算を必要とします。
以上のことから、ディープラーニングにおける推論や学習は、大規模な行列計算を伴う処理プロセスであり、高い計算処理能力を求められることがお分かりいただけるでしょう。
ディープラーニング用サーバーとGPU
現在ディープラーニング用サーバーとして販売されているコンピューターの多くはGPU(Graphics Processing Unit)を搭載しています。GPUは、その名前が示すように本来は画像処理用に開発された装置です。それがなぜディープラーニングと関係するのでしょうか。 先に述べたように、ディープラーニングでは大量の行列計算を行う必要があります。このため、ディープラーニング用のサーバーには非常に高い処理能力が求められます。これを通常のCPUで賄おうとするとCPUのコア数を大幅に増やす必要があり、サーバーのコストが大幅に上がってしまうという課題があります。 これに対して、画像処理のように高速でデータを並列処理することを目的に設計されたGPUは、ディープラーニングで多用される行列計算に適したプロセッサーと言えます。実際、行列計算では、GPUはCPUの10倍以上の処理能力を発揮することが知られています。 たとえば、10層程度のニューラルネットワークの場合、約10億個のパラメーターのチューニングが必要になると言われていますが、この計算を従来のCPUで処理しようとすると1年ぐらいの時間がかかってしまいますが、この処理をGPUで行うと、30日程度で完了することができます。 CPUと比較的安価なGPUを組み合わせ、ディープラーニングで必要な行列計算はGPUで実行し、GPUが苦手とする分岐処理やメモリーをランダムにアクセスするような処理をCPUで実行することで、コストパフォーマンスの高いディープラーニング用サーバーを構成することができます。現に、GPU Technology Conference 2016の基調講演で、IBMのチーフ・テクノジー・オフィサーであるロブ・ハイ氏はGPUを利用することでWatsonの学習速度が8.5倍向上したことを明らかにしています。CPU-GPU混成サーバーの考慮点
一般的なディープラーニング用サーバーにおけるCPUとGPUの接続概念図を図4に示します。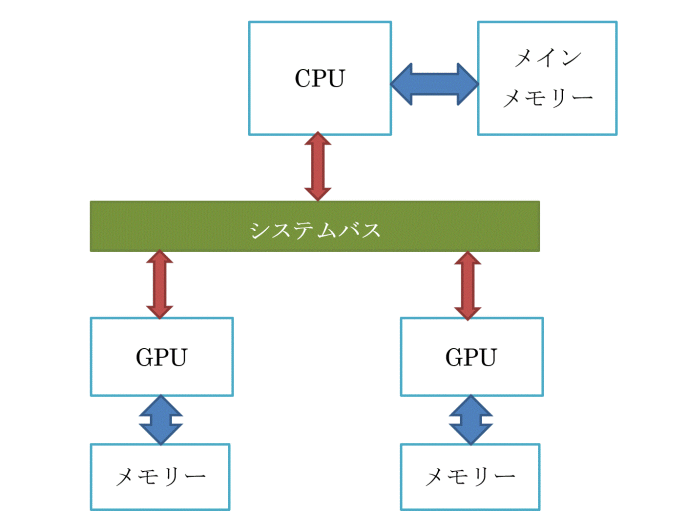 図4.CPU-GPU接続の概念図
CPUとGPUを組み合わせた構成の場合、入力データはメインメモリーからGPUのメモリーに転送され、行列計算を行った後その結果がメインメモリーに返されることになります。また入力データがGPUのメモリーに格納しきれないほど大きなサイズになる場合には、行列計算が完了するまでに何度もメインメモリーとGPUのメモリーの間でデータ転送が発生することになります。
このため、メインメモリーとGPUのメモリーの間でのデータ転送速度が遅いと、いくらCPUやGPUの処理速度が速くても、処理すべきデータが転送を完了するまではCPUおよびGPUは待ち状態になるため、システム全体の処理効率が落ちてしまいます。
したがって、CPUとGPUを組み合わせたディープラーニング用サーバーの採用に当たってはCPUやGPUの処理性能はもとより、CPUとGPUの間にあるバスの帯域幅がCPUのメインメモリーアクセス速度やGPUのメモリーアクセス速度に比べて十分かどうかも重要な考慮点になります。
続いて第3回目はiWorld編集部にバトンタッチして「OpenPOWERが拓くディープコンピューティング用サーバーの未来」です。
図4.CPU-GPU接続の概念図
CPUとGPUを組み合わせた構成の場合、入力データはメインメモリーからGPUのメモリーに転送され、行列計算を行った後その結果がメインメモリーに返されることになります。また入力データがGPUのメモリーに格納しきれないほど大きなサイズになる場合には、行列計算が完了するまでに何度もメインメモリーとGPUのメモリーの間でデータ転送が発生することになります。
このため、メインメモリーとGPUのメモリーの間でのデータ転送速度が遅いと、いくらCPUやGPUの処理速度が速くても、処理すべきデータが転送を完了するまではCPUおよびGPUは待ち状態になるため、システム全体の処理効率が落ちてしまいます。
したがって、CPUとGPUを組み合わせたディープラーニング用サーバーの採用に当たってはCPUやGPUの処理性能はもとより、CPUとGPUの間にあるバスの帯域幅がCPUのメインメモリーアクセス速度やGPUのメモリーアクセス速度に比べて十分かどうかも重要な考慮点になります。
続いて第3回目はiWorld編集部にバトンタッチして「OpenPOWERが拓くディープコンピューティング用サーバーの未来」です。
筆者
笠毛 知徳
日本アイ・ビー・エム株式会社
サーバー・システム事業部
データ・セントリック・コンピューティング営業部長
<バックナンバー>
第1回 [入門編] いまさら聞けないディープラーニング、機械学習








